MiniMax-M2-her 技术深度解析
Worlds to Dream, Stories to Live
一份关于如何在生产环境中构建真正可用的 Role-Play Agent 的技术报告。
前言:三年的观察,Role-Play 是什么?
今年是我们做 Talkie / Xingye 的第三年。
三年时间,足以让一个产品在用户生命中留下痕迹,也足以让我们从长期的使用反馈中读出一些不那么显而易见的洞见。这些规律不是产品指标的简单堆砌,它们更像是用户行为透镜下的真实需求折射。我们发现,最给我们带来 insight 的,恰恰是每一次使用背后的人。我们发现:
- 用户的“重说”按钮触发模式呈现出严重的长尾分布。当我们深入分析这些用户的按钮触发时刻,我们发现它们往往集中在叙事关键节点:角色的一次倾诉、一场误会的和解、一段期待已久的情绪交互。用户在用他们自己的方式,追求那个感觉对了的“完美瞬间”。这让我们意识到,Role-Play 的体验不是一个二元的“满意/不满意”判断,而是一条连续的追求曲线。用户真正在意的,是那些高密度的情绪峰值时刻。
- 与此对应的,我们发现平台内 NPC 的热度分布也并非常见的幂律(Power Law)。即便是最冷门的角色,也总有一小群活跃用户与之维持着数百轮的对话。对他们来说,这个角色就是唯一的。这意味着,如果我们的模型只学到了“平均值”,就会伤害到那些为小众角色付出感情的用户。平均主义在这里是一种暴力——它抹杀的是少数人眼中最重要的那部分价值。
- 用户的对话轮次与 Engagement 的相关性同样也值得关注,我们发现用户的对话轮次在第 20 轮后出现明显下降。这个信号说明,浅层的角色扮演是新鲜感驱动的;而长期的留存并不只靠一次性的爽点推动,更取决于 NPC 和用户能否在有限轮次内逐步沉淀稳定的互动链接。基于此,我们将 Engagement 的驱动力拆成短期兴趣与长期链接两类。我们一方面持续加深互动链接,另一方面通过探索提供新的爽点与动力。
这些信号最终汇聚成一个观察:Role-Play 的内核从来不在于“完美复刻一个角色”,而在于用户和这个角色共同编织的那段独一无二的旅程。更深层次的 Role-Play,是要让每个用户都能在那个世界里,拥有鲜活的体验,获得只属于自己的那个瞬间。从一个更形式化的角度,它本质刻画的是智能体在特定 {World} × {Stories} 坐标下,针对 {User Preferences} 的演绎能力。
基于此,我们将对 Role-Play 的思考,沉淀为三个重要问题:
- 如何让每个世界拥有独特的灵魂 (Worlds) ? 每个人创造的世界千差万别,从青涩校园到快意江湖,从一对一的深度羁绊到多人故事演绎,底色截然不同。如果模型只学到了“平均值”,所有角色就会千人一面,所有世界都会坍缩成同一种平庸的风格。我们需要模型具备更宽广的光谱,去支撑从热门到长尾、从主流到小众的万千世界。
- 如何让故事一直延续和保持生命力 (Stories)? 对话越长,剧情失控的风险越高。模型容易陷入机械的循环与重复,失去张力。但好的故事应该拥有呼吸感——它懂得在某些时刻推你一把,掀动情节波澜;也会在某些时刻停下来等你,给你喘息与思考的空间。
- 如何读懂用户那些未被言明的期待 (User Preferences)? 有的用户钟爱缓慢铺陈的情绪拉扯,有的用户则渴望快节奏的情节推进。用户或许不会明说“我想要这种感觉”,但模型需要在上下文中学会理解这些潜台词,贴近用户真正想要进入的节奏与心流。
第 1 章:MiniMax-M2-her
在过去的三年中,我们面对上述三个重要问题,始终在迭代我们的模型。在今天,我们正式带来 MiniMax-M2-her,它是我们通往更深层次的 Role-Play 所做的一次系统性尝试。具体来说,MiniMax-M2-her 支持:
- 独一无二的世界体验: MiniMax-M2-her 能理解并维持所构建的或宏大或细腻的复杂设定,以此为锚让每一次互动都更贴合世界观和角色的灵魂;
- 有节奏和生命的故事推进: MiniMax-M2-her 会更加拒绝平庸的重复与死板的套路,能用更鲜活的笔触,主动推进更深层次的情节,让故事像生命一样拥有张力和呼吸的节奏;
- 精准的潜在偏好理解: 它可以敏锐地理解那些未说出口的期待,从细微的交互中读懂用户的偏好,适应用户的习惯。
在下面的章节中,我们将这三年对这个行业的理解,以及我们为 MiniMax-M2-her 做的事情进行一个总结。
第 2 章:从评测说起 - A/B 测试真的是好评估吗?
在 2024 年中之前,我们(包括我们已知的一些同行)都通过 A/B 测试进行模型迭代,通常的观测指标是 lt、停留时长以及平均对话轮数。
但是我们很快发现这种迭代方式有一个巨大的问题:如果要拿到一个置信的结果,A/B 测试的周期通常会比较长,反馈周期可能会长达一周。此外,A/B 测试在有上下文的场景下会出现因果逆转的问题。总而言之,为了解决 A/B 测试迭代周期较长的问题,我们试图通过离线评估来近似真实的 A/B 测试结果。但 Role-Play 不存在可验证的正确答案,即它是 Non-verifiable(不可验证)的。我们发现:虽然我们很难定义什么回答能够对齐用户偏好(aligned),但是我们可以定义什么回答无法对齐用户偏好(misaligned)。
基于这个观察,我们提出了一个几乎对齐线上评估的 Role-Play Bench。它旨在通过情境重演(Situated Reenactment)的方式,自动化评估模型的 misalignment 现象。
2.1 Situated Reenactment:对齐线上的核心
情境重演旨在衡量模型在特定 {World} × {Stories} 坐标下,针对 {User Preferences} 的演绎能力。给定 {NPC Prompt + User Prompt + Relationship Setup + Context},我们通过 Model-on-Model 的 Self-Play 机制生成多轮对话轨迹,观测模型在交互中的表现。
2.2 Role-Play 的评估维度
我们将 misalignment 抽象为三个维度:Worlds(基础负向、逻辑混淆、事实性错误)、Stories(内容推进与多样性、内容逻辑)、User Preferences(用户交互质量)。
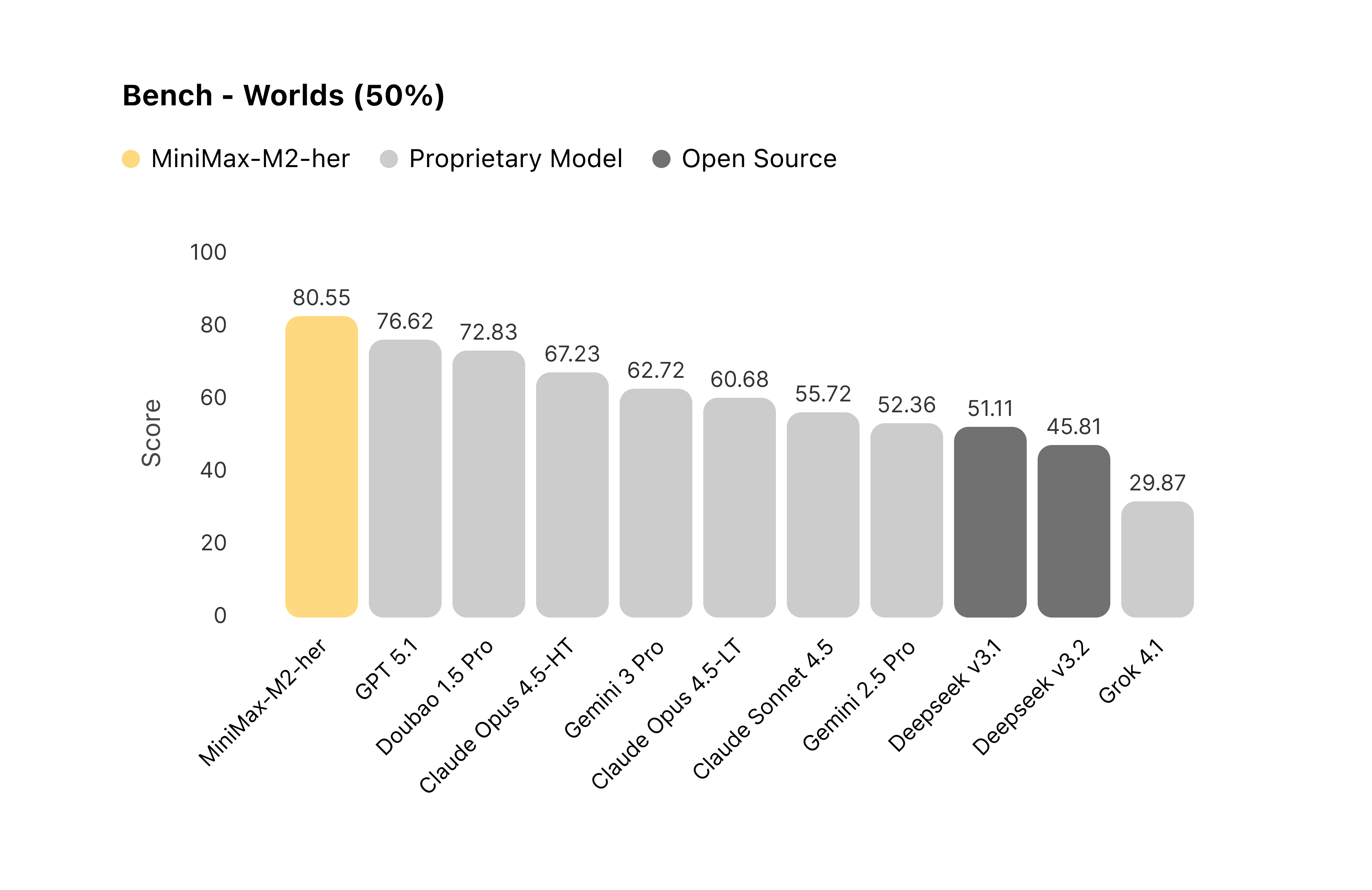
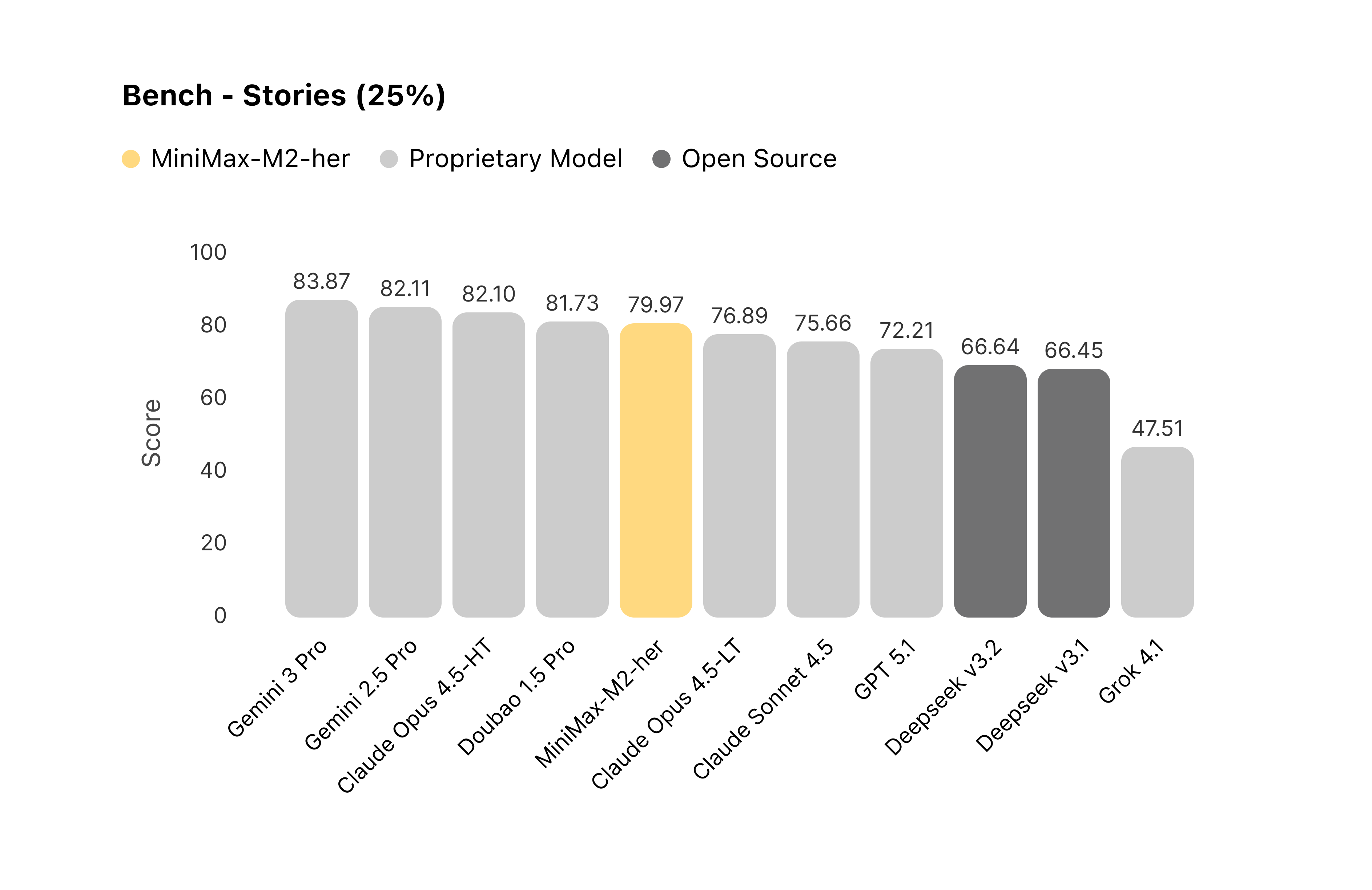
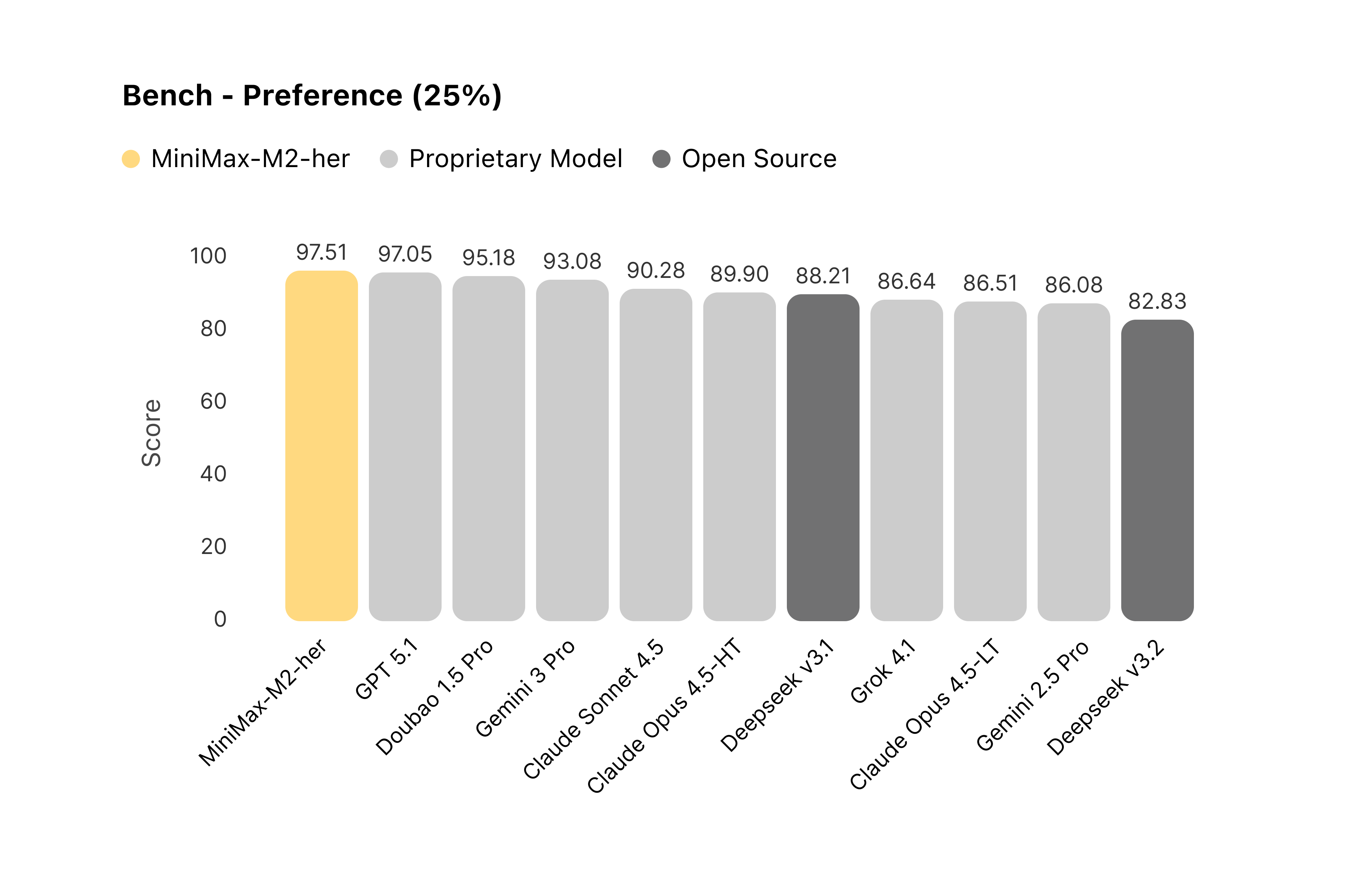
2.3 Role-Play Bench 评估结果
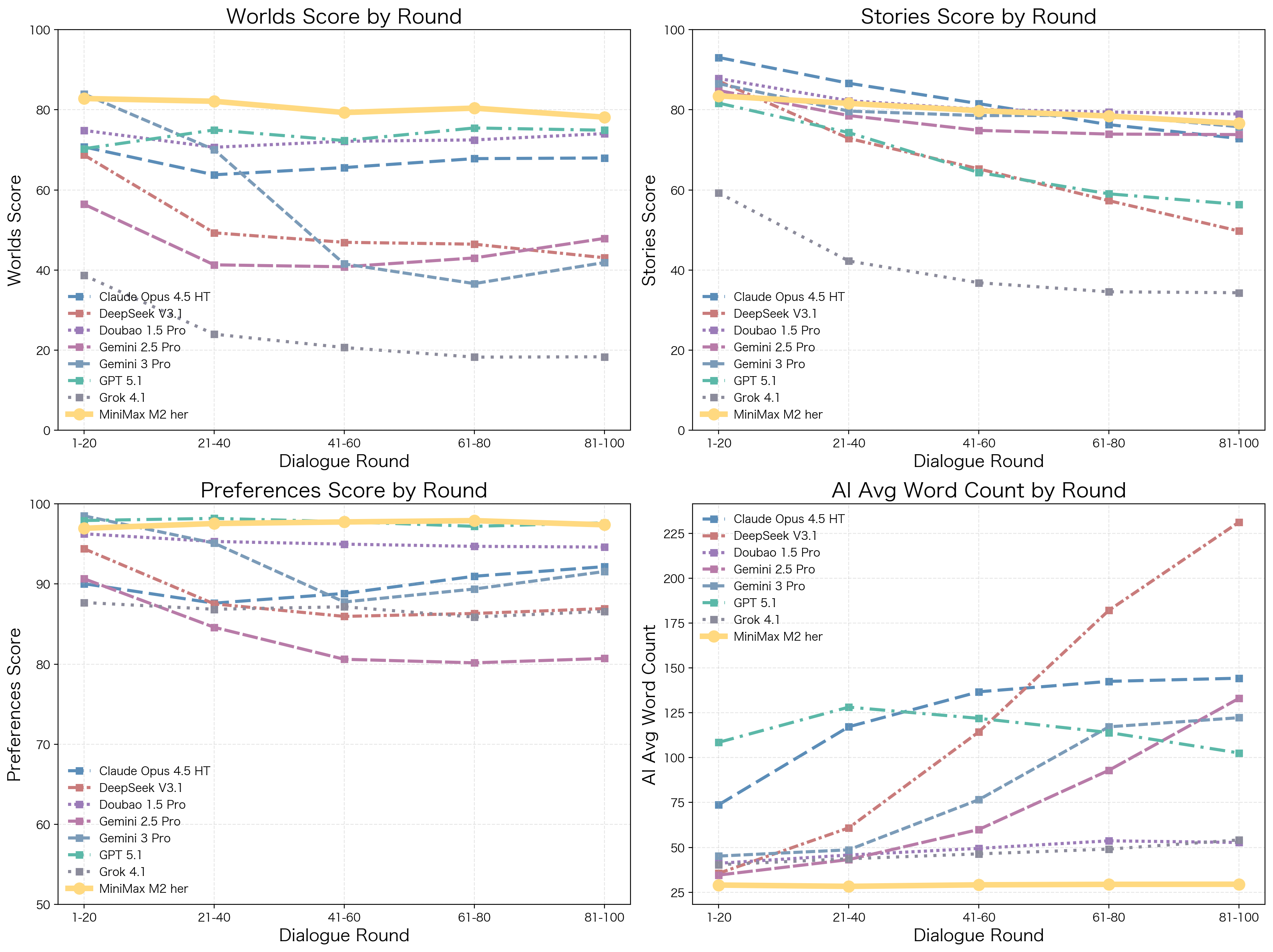
我们基于 Role-Play Bench 对主流模型进行了系统评测。在 100 轮的长程对话交互中,MiniMax-M2-her 综合表现位居榜首。
图 1:对比各模型在 Role-Play Bench 上的对话表现

图 2:对比各模型在 Worlds 维度的表现

图 3:对比各模型在 Stories 维度的表现
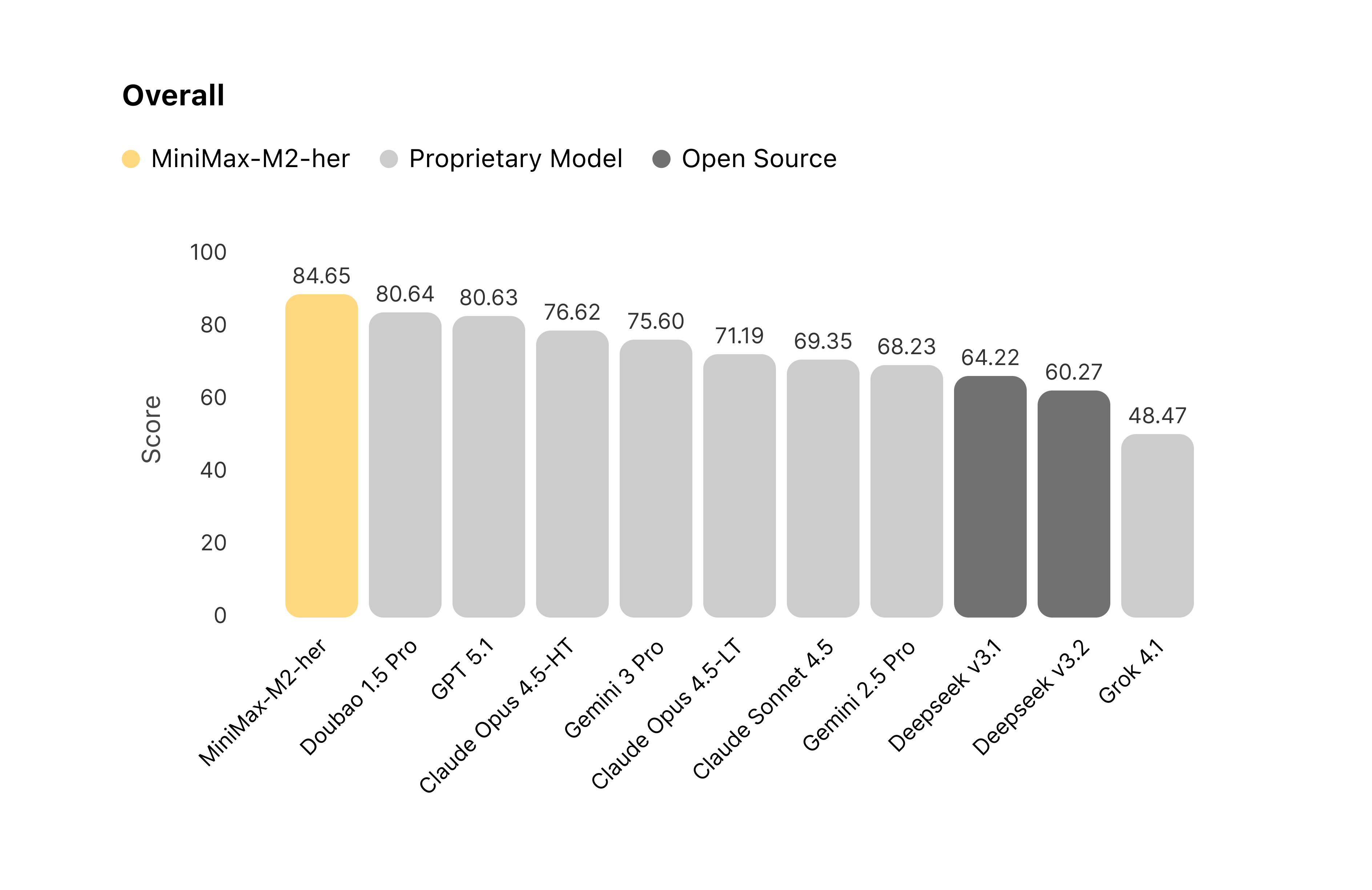
图 4:对比各模型在 Preferences 维度的表现

图 5:各模型随轮次变化的质量与字数趋势图
第 3 章:MiniMax-M2-her 是如何构建的?
我们通过合成数据的方式缓解 misalignment 问题,在保证输出多样性的前提下,抬高模型在世界观理解和故事推进的能力下限;之后结合数据团队的反馈信号提升模型对用户偏好的感知。
3.1 Agentic Data Synthesis
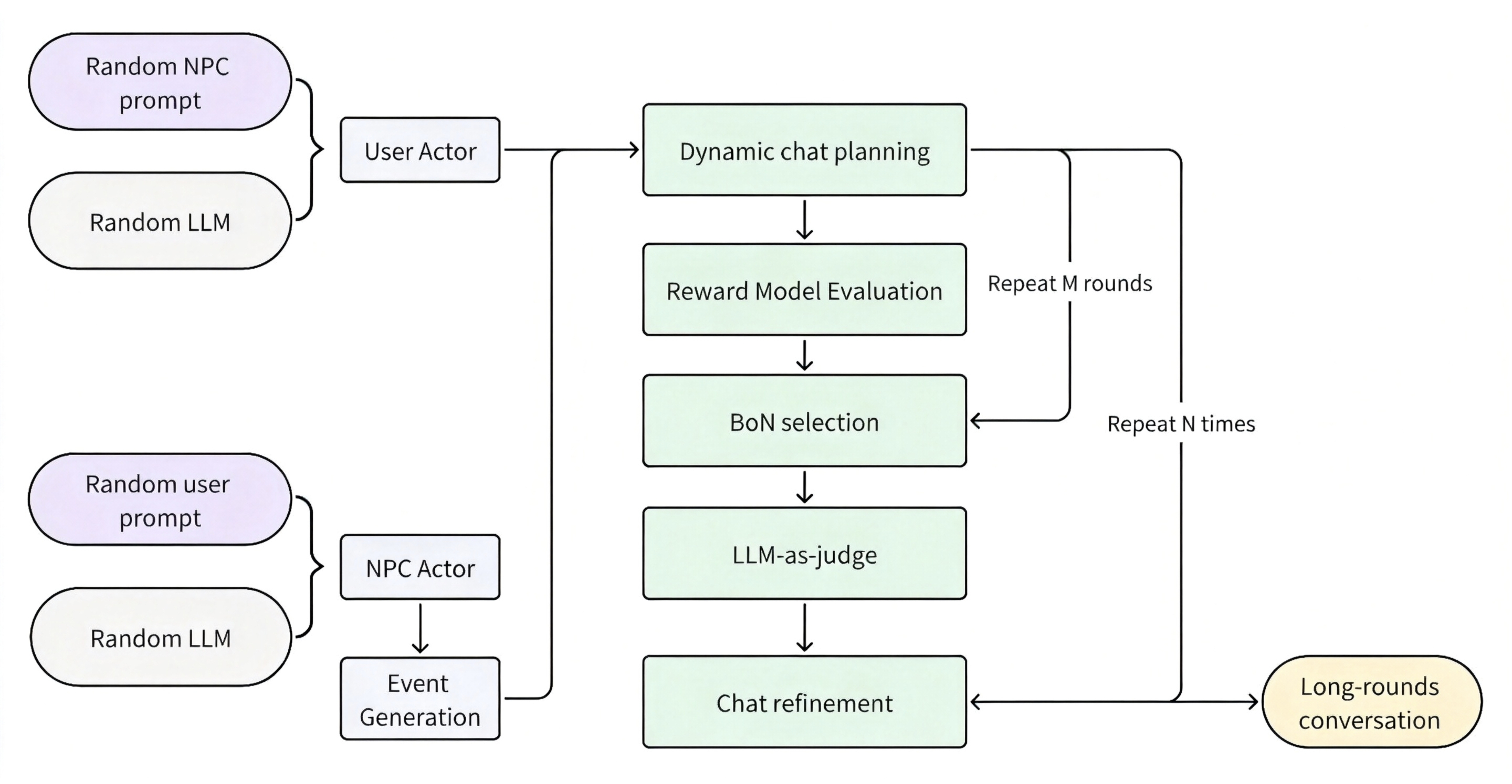
我们开发了一套基于 agentic 工作流的对话合成管线,用于生成高质量且多样的对话数据。管线通过专家模型库 Self-Play、reward model 打分过滤、LLM-as-judge 改写、以及规划智能体引导等多个环节保障质量与多样性。
图 6:合成数据管线概览
3.2 Online Preference Learning
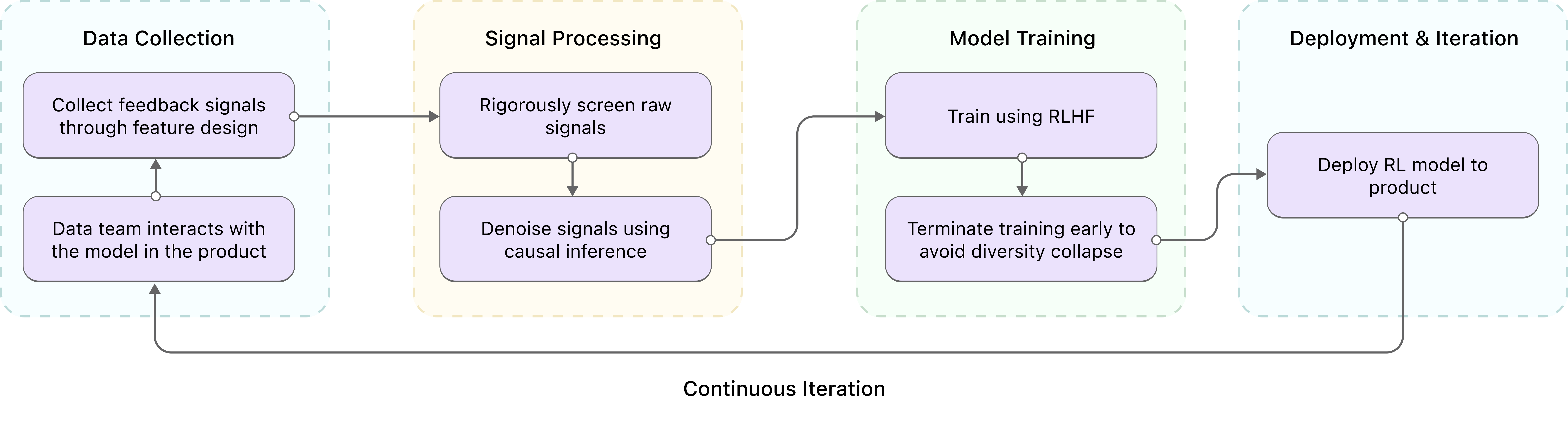
我们通过收集隐式信号和情境化偏好,并采用 online RLHF 的方式训练模型,提升对用户偏好的感知。核心流程包括:数据团队交互收集反馈信号、因果推断去噪、RLHF 训练(提前终止防止多样性坍缩)、循环迭代部署。
图 7:Online Preference Learning 流程概览
第 4 章:未来做什么?
下一阶段的命题是“如何让用户真正拥有一个可以探索、可以改变、可以生长的世界”。我们将这个方向称为 Worldplay——一种让用户从“进入预设世界”升级为“共同创造世界”的交互范式。核心方向包括动态 World State 建模和多角色协同。
Worlds to Dream, Stories to Live. Let's go together.