MaxProof: 生成式验证强化学习驱动的数学证明进化系统
简介
在 M3 发布推文中,我们汇报了 M3 模型在 IMO 2025 与 USAMO 2026 两组国际数学竞赛真题上的表现:在搭配 MaxProof 框架后,M3 均超过了人类金牌线。本文将进一步展开我们在推进数学证明能力过程中的技术路径,包括基座模型能力增强、verifier 对齐、refinement 能力构建,以及测试时增强框架 MaxProof 的设计。
从 Gemini Deep Thinking 在 IMO 2025 中达到金牌水平,到 DeepSeek-Math-V2 成为首个开源金牌能力模型,再到 SU-01、NVIDIA Nemotron Cascade2 等工作在更小模型上实现面向数学竞赛的专用能力,以及 GPT 5.5 解决长期困扰数学家的开放问题,模型正在持续进入更高难度的数学问题空间。在 M2 到 M3 的迭代周期中,我们也尝试将这种更强的数学证明与自我改进能力融入最终发布的通用模型。
从方法论上看,让模型在 one-shot 场景下解出高难度数学题,开源社区已经给出了一条相对清晰的路线:先把模型的 best@K 能力提升到足够高,再通过 test-time scaling 将 best@K 转化为更稳定的 pass@1。我们的方案也沿着这两个方向展开。第一部分是基模能力提升:通过三个 expert model 同步增强模型的证明生成、错误判断与证明修复能力。第二部分是测试时增强:我们设计了一个类进化搜索的 TTS 框架 MaxProof,让最终 M3 合板模型能够进行多轮自迭代解题。本文会重点介绍其中的训练特性、系统设计取舍,以及我们在实践中得到的一些经验。
基模能力提升
本节介绍我们如何在单模型侧构建数学证明与自我改进所需的几个原子能力。
总体布局
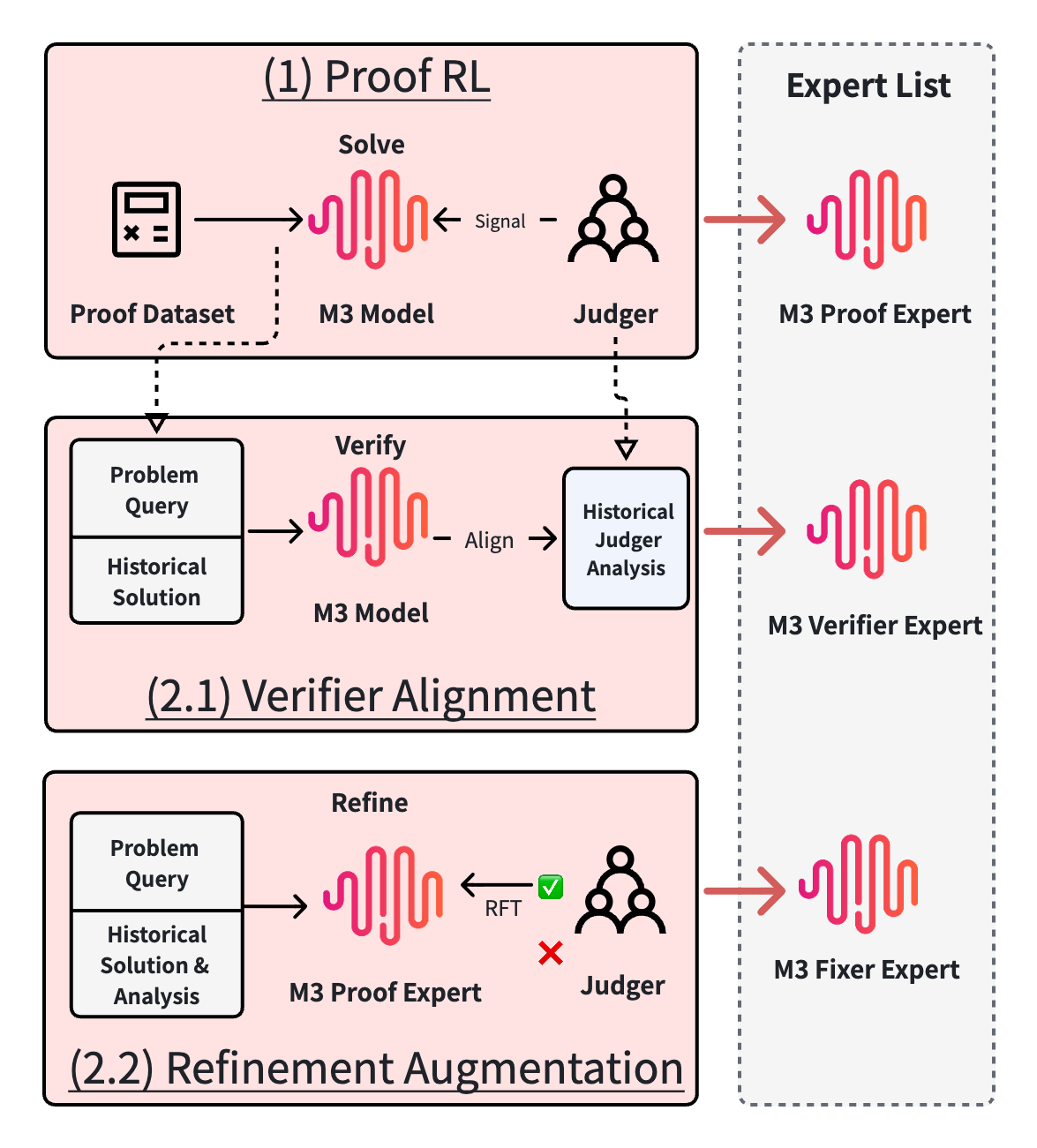
Part 1 Overview:在基模能力提升上,我们进行了三阶段的模型增强,产出三个专家模型。1阶段Proof RL,目标是产出 Proof Expert。我们通过 RL post-training 构建数学题 reward system,对模型候选证明进行评分,并进行长程强化学习。2.1阶段Verifier Alignment,产出 Verifier Expert:我们利用 Proof RL 阶段积累的 golden verification analysis,将 verifier alignment 建模为 error finding 任务,并通过 RL 对齐模型的错误定位与判别能力。2.2阶段Refinement Augmentation,产出 Fixed Expert:我们复用 Proof RL 阶段自然产生的 (historical flawed proof, verification analysis) pairs,通过 rejection sampling 继续微调 Proof Expert,让模型学会基于错误诊断修复已有证明。这三部分产出的expert model都用在M3模型的最终合板训练中。
Proof RL:重generative verifier的一次实践探索
Proof RL 的目标是在 M3 上进行长程 RL 训练,提升模型直接生成数学证明的能力。相比传统 RLVR,我们最大的变化是将 reward 主要交给 generative verifier 提供。这带来了一个直接挑战:训练过程必须系统性处理 reward 信号不准、noise、false positive 与 reward hacking 等问题。
在相关工作中,DeepSeek-Math-V2 是开源社区较早展示稳定使用 generative verifier 训练困难数学题能力的案例,其核心思路是 self-verify + meta-verify。我们没有采用完全相同的路线,主要原因是 M 系列模型在历史周期内的 verify 能力积累仍然不足,短期内很难让模型自给自足地产生足够可靠的 reward signal。
因此,在这一阶段我们首先聚焦 Proof 能力提升,并采用外部前沿模型作为 generative verifier。整个系统的关键设计包括三部分:verifier 设计、RL 算法改动与训练数据准备。
Verifier设计:低False Positive enable 长程且稳定的RL过程
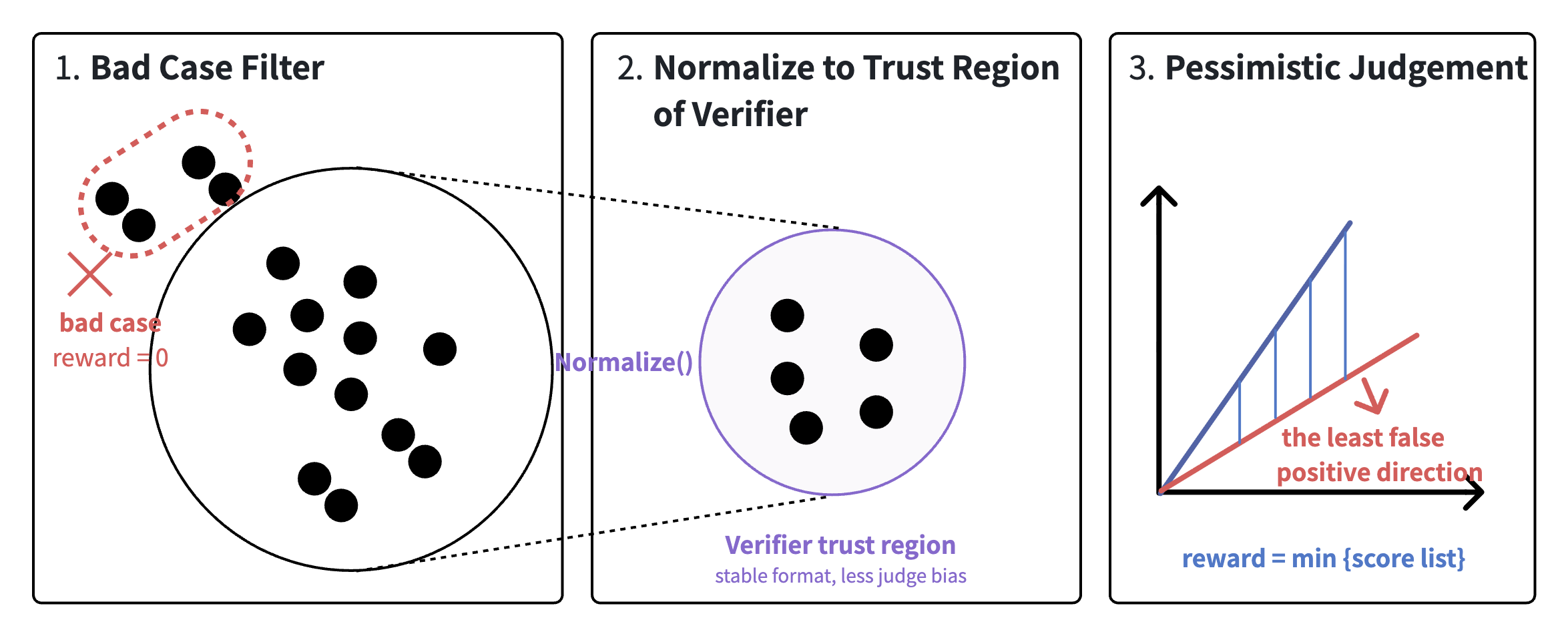
Proof RL Verifier 的设计哲学:在于将嘈杂、异质的信号投射到一个可控、可信的子空间——这是系统可靠推理能力的核心基石。原始 candidate 空间充满了多样化的解法、噪声样本以及潜在的失败模式:从极端冗长的推理链到格式偏离规范的尝试,每一个都是学习过程中的潜在干扰。Verifier 的任务是将这一混沌信号严格筛选、结构化,并以算法化的方式生成稳定奖励信号。首先,它执行异常剔除(Outlier Filtering):匹配已知失败模式或明显违规的候选输出会被直接置零,这一操作在数学上相当于对信号空间进行硬约束,防止误导强化学习更新。其次,它进行解法规范化(Solution Normalization):将多源、多风格的证明映射到统一的信任子空间(verifier trust region),减少评判偏差,使奖励信号更多反映推理质量而非表现形式差异。这一步类似于在高维候选空间上施加投影操作,将复杂异构信号压缩到可信的子流形上。最后,它应用**悲观聚合(Pessimistic Judgement)**策略:对于来自多个 verifier 的评分,取下界而非上界,以保守原则生成最终奖励。数学上,这保证了系统的鲁棒性,使强化学习在面对噪声与不确定性时依然稳定收敛。
任务定义
我们定义这个任务的通用表达形式是:
def score(problem_metadata, candidate_solution):
candidate_solution = strip_thinking(candidate_solution)
verifier_prompt = construct_prompt(
problem_metadata,
candidate_solution,
)
score = verifier(verifier_prompt)
assert score in [0, 1]
return score打分过程返回 0-1 区间的连续分数。Verifier 会根据题目元信息,对 candidate solution 的完成程度和数学严谨性进行评估。在我们的设置中,verifier model 主要使用最新的frontier model。
具体设计
多轮训练调优后,我们发现:只在静态评测上获得一个“看起来足够准确”的 verifier 远远不够。Generative verifier 天然存在不稳定性,而这种不稳定在 RL 中会被 policy 持续放大,最终可能导致训练崩溃。我们在 M2 周期中已经观察到过类似问题,因此在 M3 周期里采用了一个更保守的原则:
当 generative verifier 被用于 RL reward 时,长期稳定训练的优先级不是提高平均准确率,而是尽可能压低 false positive。即使这会带来更高的 false negative,也要让可被 policy 优化的空间足够窄。
基于这个原则,我们将 reward system 设计成分层防御结构。
- Bad case 防御:通过多层代码级规则阻断明显异常的模型输出(如思考不聚合、超长solution等),一旦命中 bad case,就跳过后续 verifier 调用并直接给零分,避免低质量输出意外获得奖励。
- Pattern 偏移防御:M2 周期的经验表明,reward hacking 很多时候并不是“解题能力突然提升”,而是输出风格迁移到了 verifier 偏好的格式。为了降低 verifier 对特定表达模式的偏好,我们在进入 generative verifier 前会先进行格式归一化,使 candidate solution 尽量处在同一评估分布下。
- 多维度悲观聚合:我们同时使用多模型、多模式 verifier。双模型设置可以降低训练向单一 judge 偏移的风险;双模式设置则包含 with rubrics 与 without rubrics 两类评估方式。前者借助人工或模型标注的 grading scheme 增强评分锚点,后者要求 verifier 独立寻找明显错误,防止 policy 过度拟合 rubrics pattern。最终聚合时,我们采用偏悲观的下界估计:只有当多个 verifier 都认可时,candidate 才能获得高分。
这是一套相对重的 verify 流程,训练速度也因此明显变慢。但从我们的实践看,收窄 reward 优化空间是对抗 reward hacking 最有效的方式之一。相比让 policy 更快获得奖励,我们更关心 reward 是否足够可信,尤其是 false positive 是否被压到足够低。
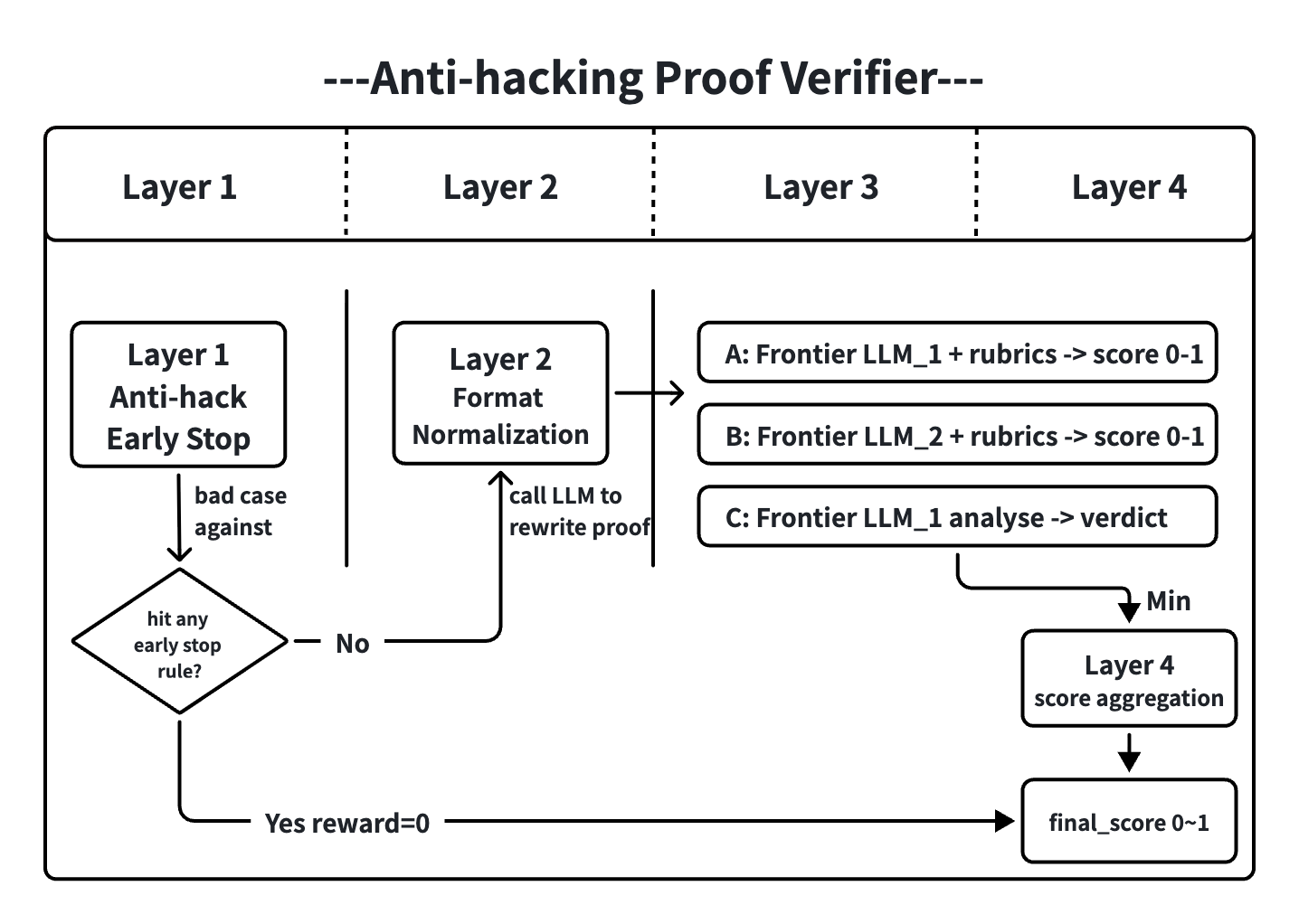
Proof RL Verifier分层设计:以获得具备高anti-hacking能力的reward来源,Layer 1: 阻断模型输出bad case,一旦匹配badcase就跳过后续操作直接给零分。Layer 2: 对candidate solution进行格式归一化操作,调用模型将模型输出归一化到统一的格式。Layer 3: generative verifier的真正调用,采用多模型多模式的手段,并行调用三种设置不同的verifier来获得多个分数。Layer 4: 分数聚合,使用悲观估计的方式,多个来源的分数取最小值作为最终分数。
RL姿势:剔除干扰样本,换取更准确训练信息的学习方向
在 RL 算法上,我们沿用了 M2 周期中的 CISPO,并以 forge 作为训练框架。针对数学证明任务,我们只做了较轻量的改动,核心是让 reward 信号更稳定,而不是引入复杂的 process-level reward。
具体来说,我们直接将 verifier 给出的 0-1 连续分数作为整条 trajectory 的 reward,没有进一步切分为 step-level 或 process-level 信号。连续 reward 相比纯 0/1 reward 更稠密:即使一组样本都只是部分正确,也仍然可能形成可学习的相对差异。但它也会放大 verifier 自身的不稳定性,尤其是在不同 candidate 得分接近时,微小噪声可能被误当成真实偏好。
为此,我们引入了 std threshold filter:在 group 内 reward 方差过低时,直接过滤这组样本,不参与更新。直觉上,如果一组样本的 reward 差异很小,那么其中包含的学习方向更可能是噪声;只有当 group 内存在足够显著的 reward 差异时,我们才认为它提供了更可靠的优化信号。
数据准备:细致的domain与trick平衡
训练数据主要来自互联网公开数学奥赛类型题目。在数据挖掘与清洗阶段,我们为每道题构建以下元信息:
| 字段 | 内容 |
|---|---|
| Problem Statement | 题干 |
| Reference Solution | 人类专家给出的完整解题过程,通常来自论坛评论区,用于后续标注 grading scheme |
| Domain | 题目所属数学分支,例如组合、几何、代数等 |
| Solving Trick | 题目涉及的具体解题技巧,来自我们构建的 trick taxonomy |
| Grading Scheme | 基于人工标注 few-shot,由模型辅助生成的评分标准 |
在进入最终 RL 训练前,我们继续做了三步后处理:
| 步骤 | 目的 |
|---|---|
| 难度筛选 | 以 M2.7 作为 baseline 过滤过于简单的题目,减少训练预算浪费 |
| Domain 平衡 | 按数学分支平衡数据分布,避免训练被单一题型主导 |
| Trick 平衡 | 控制高频解题技巧的占比,同时保留竞赛题真实分布中的长尾结构 |
这种处理方式的目标不是构造一个完全均匀的数据集,而是在覆盖真实竞赛分布的同时,降低少数高频 domain 或 trick 对训练的主导作用。
M2周期Bitter Lesson:一个典型的Reward hacking case study
在 M2 周期中,我们也做过类似尝试。当时的 verifier 采用了相对简单的单 rubrics judge 形式。训练指标一开始看起来持续变好,但进一步分析后,我们发现 policy 实际上学到了一些典型的 hacking 模式。
为了定位这类问题,我们后来把训练过程中的异常信号整理成 reward hacking detection dashboard。这个 dashboard 不只看最终 reward,而是同时监控九类信号:train/eval score gap、分数分布是否出现异常双峰、visible/thinking length 的漂移、proof 与 non-proof 样本的分数差异、结构模板收敛、开头 pattern 收敛、thinking 中的“Wait”式自我修正频率、hand-waving pattern,以及一个综合 hack score。这样做的目的,是尽早发现“训练分数上涨但真实解题能力没有同步提升”的分布偏移。
我们观察到的典型 hacking 模式包括:
- Length bias:模型输出的 solution 越来越长,visible length 与 thinking length 都会随训练推进而上升。长文本更容易覆盖 rubrics 中的关键词,也更容易让 verifier 误以为论证充分。
- Format hacking:模型开始模仿参考解法或 rubrics 的表面格式,例如固定的 step header、verification section、final answer section,以及特定 opening pattern。输出看起来更像“标准答案”,但数学内容并不一定更可靠。
- Semantic shortcut / hand-waving:模型会在关键位置使用“it can be shown”“after simplification”等跳步表达,把真正困难的推导压缩成未证明断言。这类样本在人工检查中很容易发现问题,但在单一 verifier 下有时会获得过高分数。
- Judge-specific preference:policy 会逐渐靠近某个 judge 偏好的表达分布。一旦 reward 来源过于单一,训练就可能优化出“更会取悦 judge 的证明”,而不是更正确的证明。
这些经验直接影响了 M3 周期的 verifier 设计。我们的主要 takeaway 是:在高难数学证明 RL 中,reward hacking 往往不是突然出现的离散事件,而是输出分布缓慢偏移的结果。静态评测无法完全暴露这个问题,必须在训练过程中持续监控输出形态、reward 分布、长度变化、模板收敛、hand-waving 频率和 verifier disagreement。更重要的是,reward system 要主动限制 policy 可钻的空子,而不是等到 hacking 出现后再补救。
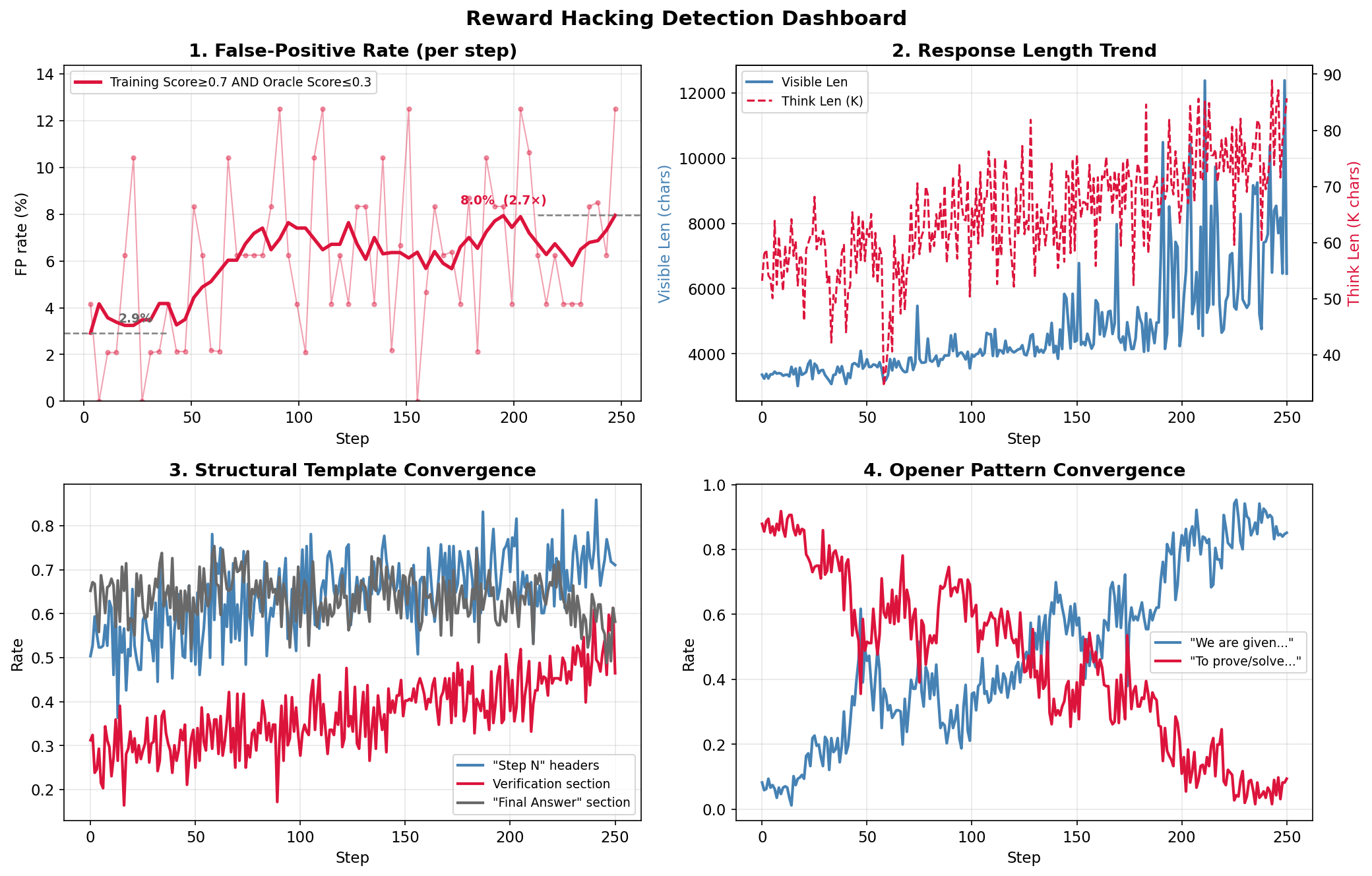
M2 周期 Proof RL reward hacking 案例研究: (1) 用独立 oracle 评分对比训练时使用的打分方式, false-positive rate (即「训练分数高 ≥0.7 但 oracle 分数低 ≤0.3」的样本占比) 在训练过程中从约 2.9% 翻到 8.0%, 翻了 2.7 倍 —— 这意味着模型越训越多地生成了「看起来好但其实错」的 solution. (2) Length bias: 模型除了 thinking 长度变长之外, visible candidate solution 长度也近乎翻 3 倍 (3.5K → 10K chars), 这是一个危险的信号. (3) "Step N" 标题与 "Verification" 段落等结构化模板的出现率收敛到 70-80%. (4) 开篇句式发生几乎彻底的翻转, "To prove / To solve..." 从约 80% 跌到 10%, "We are given..." 从 10% 升到 90%. 模型实际上没在提升数学正确性, 而是学会了 LLM judge 偏好的表层风格特征 —— 这就是 reward hacking 的其中一种典型表现.
pencil2 Proof RL 中,Verifier 的使命并非简单地区分对错,而是在充满噪声、投机与偶然性的搜索空间中,构建一个真正可信的奖励世界。原始 candidate 如同未经筛选的矿石,其中既包含闪耀的真知,也混杂着冗长、投机乃至错误的推理轨迹。为了让强化学习获得稳定而可靠的优化方向,Verifier 必须将这些信号逐步投射到一个可控、可信且可验证的子空间。
从剔除异常、统一表征,到保守聚合,Verifier 的本质是在混沌中建立秩序,在噪声中提炼真相。它所守护的,不仅是一个奖励函数,更是整个 Proof RL 系统通向可靠推理能力的基石。
Verifier Alignment
提升模型在数学难题上的能力,"判断一个证明对不对"是和"写一个证明"同等重要的原子能力。一个能稳定指出证明中错误位置与本质的 verifier,本身就是数学推理能力的一部分——它支撑着自我检查、错误纠正、以及更长链路的多轮自迭代。我们因此在 Proof RL 之外单独训练一个 Verifier Expert,让 M3 自身具备这种原子能力。
任务建模:error finding 与分类联合
把 verifier 训练做成"给 candidate proof 输出一个 verdict 分类"是最直接的建模方式,但我们刻意避开了这条路径。如果只让模型预测一个 4 类标签(no_errors / minor_gaps / has_errors / fundamentally_wrong),训练信号停留在 label 层面,模型可以通过 candidate 的表面 pattern 学到一个还不错的分类器,但并没有真正"读懂"证明——它学不到定位错误、解释错误的能力。
我们因此把任务定义为 error finding + 分类的联合任务:模型必须先产出对证明每个关键步骤的分析、显式列出错误位置与描述,再据此给出 verdict。两部分都被 reward 监督——verdict 必须与 golden 对齐,errors 必须与 golden errors 在语义层面匹配。这样的建模强制模型把"哪里错了"显式表达出来,verifier 才真正成为一个可被问责的能力,而不是一个浅层分类器。
模型输出格式与 Proof RL 阶段的 verifier 系统一致:
<assessment>对证明的逐步分析</assessment>
<errors>
1. ...(具体错误描述,"none" 表示无错)
2. ...
</errors>
<verdict>no_errors / minor_gaps / has_errors / fundamentally_wrong</verdict>训练数据:直接利用proof RL阶段历史数据二次利用
对齐目标不是任一单一 judge,而是 Proof RL 中经过 min 聚合后实际起作用的最终 verifier——即多个 judge 通过悲观 min 聚合后得到的最终 verdict 与错误描述。这与 Proof RL 阶段用于给 policy 打分的最终 reward 信号同源,保证 Verifier Expert 学到的判别标准与 Proof Expert 训练时面对的判别标准一致。
数据来自 Proof RL 阶段的 validate split,按 prompt 严格切分以防泄漏。原始数据中 no_errors 与 has_errors 主导(合计约 65%),minor_gaps 与 fundamentally_wrong 偏少。我们对四类 verdict 做了平衡处理,避免训练时 verifier 偏向输出极端档(no_errors / fundamentally_wrong)或丢失中间档(minor_gaps)的判别能力。
Verifier RL 训练:双目标优化
Base 是 M3 base,与 Proof Expert 同源。
Reward 直接对应 error-finding + 分类联合的建模:
R = 0.7 · R_error + 0.3 · R_verdict- R_error LLM-based 语义对齐,主奖错误定位与描述质量
- R_verdict 按 4 档 ordering 距离打分(distance 0/1/≥2 分别给 1.0/0.5/0),监督 verdict 一致性
这一权重结构让 verdict 不能脱离 errors 单独优化——只押 verdict 拿不到 reward 主体,必须同时把错误说对,model 才能拿到高分。
Refinement Augmentation
Proof Expert 解决了"从零开始写出一个证明",Verifier Expert 解决了"判断一个证明对不对"。但在数学难题求解的实际链路中还有第三种原子能力——给定一个已有证明和它的错误诊断,写出修正后的证明。这种"refine 已有证明"的能力与"从零生成"是不同的:refine 需要模型理解原证明的结构、定位 critique 指向的具体步骤、并在保留正确部分的前提下针对性修补。我们把这一阶段称为 Refinement Augmentation,产出 Fixed Expert。
任务建模
Refine 任务的输入是一个三元组:
(problem, flawed_proof, verification_analysis)其中 flawed_proof 是一个被判定有问题的候选证明,verification_analysis 是对应的错误诊断(错误位置 + 错误描述 + verdict)。模型输出修正后的新证明。
训练数据:1 阶段proof rl的天然积累
数据完全来自 Proof RL 阶段的副产物。在 Proof RL 训练过程中,policy 在每个 iter 都会产出大量 candidate proof,外部 verifier 会给每个候选附上完整的 analysis 与 verdict。其中被判为 minor_gaps / has_errors / fundamentally_wrong 的候选,就是天然的 (flawed_proof, verification_analysis) 配对——错误真实存在、诊断也真实存在,无需额外标注。
训练方法:Rejection Sampling 微调
我们采用 Rejection Sampling 的方式对 Proof Expert 做继续微调:
- 对每条 (problem, flawed_proof, verification_analysis),让 Proof Expert 在 refine prompt 下采样多条修正证明
- 用与 Proof RL 同源的最终 verifier 对每条采样进行打分
- 保留 verdict 提升到 no_errors 或 minor_gaps 的成功修正样本,作为 SFT 训练数据
- 用筛选后的数据继续微调 Proof Expert,得到 Fixed Expert
这种 rejection sampling 的方式保证训练数据全部是"实际成功的 refine 行为",避免引入低质量修正噪音;同时由于打分用的是与 Proof RL 同源的 verifier,refine 能力的判别标准与 Proof Expert 训练时面对的标准一致。
测试时增强 MaxProof 框架
设计哲学:把测试时增强建模为一个进化搜索过程
当解题模型已经具备足够 best@K 能力之后,从 best@K 到 pass@1 的桥梁,本质上是一个 在不可微的解空间里做 guided 搜索 的问题。MaxProof 框架的设计哲学,就是把这个问题建模为一个标准的进化算法(evolutionary search):
| 进化算法概念 | MaxProof 对应组件 |
|---|---|
| Population(种群) | 候选解池 |
| Fitness function(适应度) | Verifier 给出的 reward |
| Selection(选择) | 按 reward 选 top-M parent |
| Mutation / Crossover(变异 / 重组) | Refine 操作(PATCH 局部修复 + REWRITE 重新探索) |
| Crossover signal(重组信号) | Sibling candidate 的 summary,作为"其他个体的经验"输入 refine |
| Elitism(精英保留) | 已被认为完美的 candidate 不再 mutate,直接保留进决赛 |
| Tournament selection(锦标赛选择) | 最终 self-pick 阶段的 pairwise ranker tournament |
| Convergence criterion(终止条件) | Adaptive early stop(多 individual 同时达到 fitness 上限) |
这套映射不是事后凑出来的标签——它对应了三个我们认为 TTS 框架必须解决的核心问题:
第一,如何从一个 single-shot 不可靠的 generator 里得到"群体的智慧"?答案是采样多个 candidate,把噪声拍平到 population 层面。
第二,群体里有好有坏,如何利用群体信息让差的变好?答案是 selection + mutation:让好的 candidate 当 parent,生成它的改进版本;并通过 sibling cross-learning,让 mutation 不仅参考 parent 自身的缺陷,也参考其他个体的失败模式。
第三,如何从最终群体里挑出最好的 individual?答案是 fitness 单独不够(noisy),需要 tournament 形式的 pairwise comparison 来降噪。
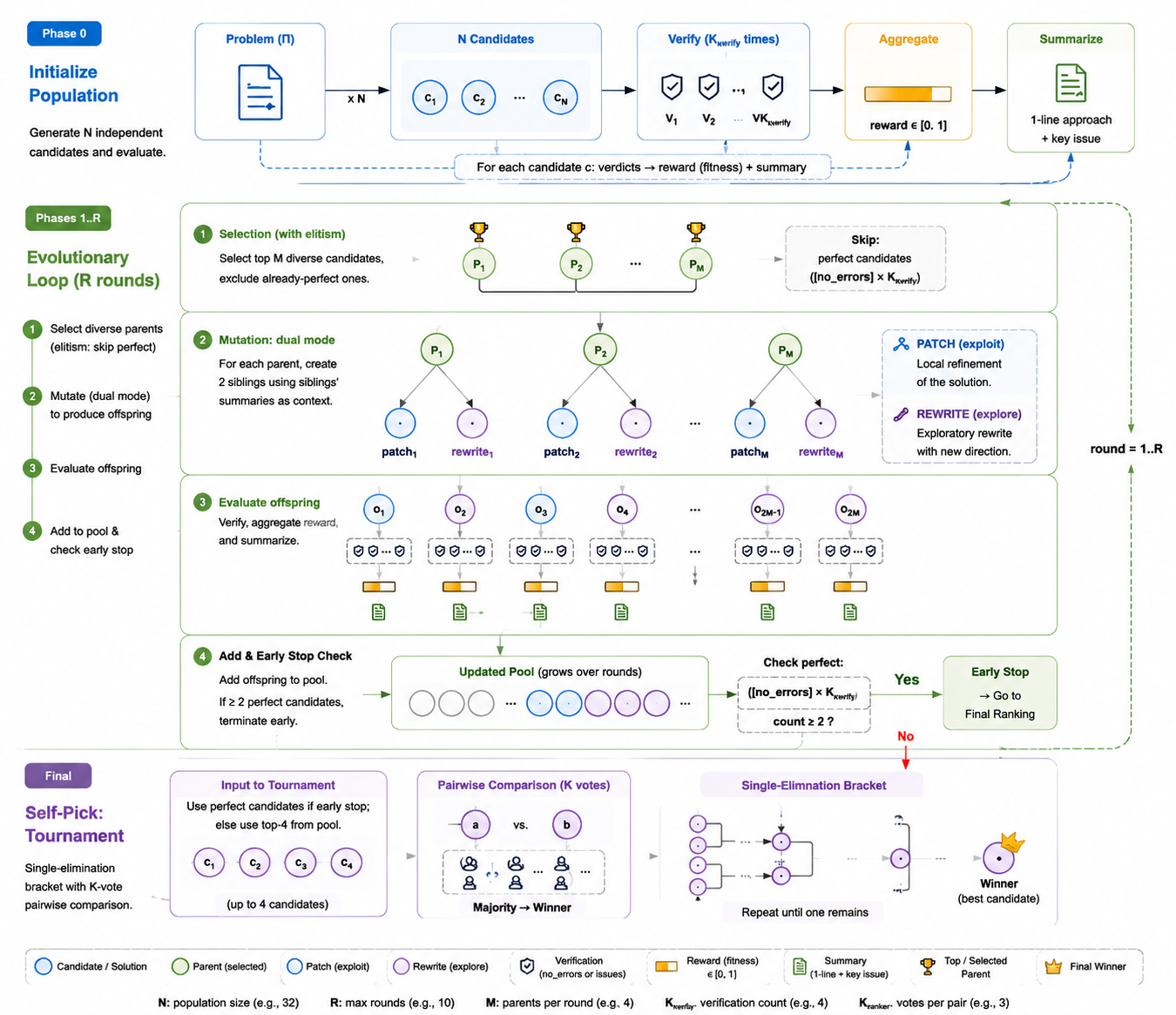
MaxProof TTS 算法的完整流程:一组典型配置是:初始化采样 N=32 个候选解,每个候选独立验证 K_verify=4 次;进化循环最多运行 R=10 轮,每轮选择 M=4 个 diverse parents;最终 ranker tournament 中每组 pairwise comparison 使用 K_ranker=3 票做多数决。实际部署时这些参数可以按题目难度和推理预算调整。1. Population initialization:对输入问题生成 `N` 个独立候选解。每个 candidate 都会被独立验证 `K_verify` 次,再聚合为 `reward / fitness ∈ [0, 1]`,同时生成一条 summary,记录该解法的一句话思路与关键问题。2. Selection with elitism:每一轮从候选池中选择 top-M diverse parents。已经达到 perfect verdict 的 candidate 不再参与 mutation,而是通过 elitism 保留到后续 final ranking。3. Dual-mode mutation:对每个 parent 同时生成两个 sibling:PATCH 负责 exploit,对已有证明做局部修复;REWRITE 负责 explore,从新方向重新组织证明。Refine prompt 会引入 sibling summaries 作为上下文,让 offspring 能吸收其他候选的失败模式和局部洞见。4. Offspring evaluation:对子候选再次执行多路 verifier、reward aggregation 与 summary 生成,并将结果加入候选池。5. Adaptive early stop:如果候选池中至少两个 candidate 在 `K_verify` 次验证中都达到 `no_errors`,则提前停止进化,进入最终排序;否则继续下一轮,直到达到最大轮数。6. Self-pick tournament:如果触发 early stop,则使用 perfect candidates 进入锦标赛;否则取候选池 top-4。每场 pairwise comparison 由多个 ranker votes 做多数决,单淘汰直到只剩一个 final best candidate。
框架的几个关键设计约束
进化算法的有效性建立在几条结构性假设之上,这里把 MaxProof 把它们落到具体设计的方式简单说一下。
Fitness function 必须可信。Verifier 的输出直接驱动整个进化过程:fitness 错了,selection 和 termination 都会被污染,整个搜索会朝错误方向收敛。我们在 prompt 层面做了相当严格的约束,要求 verifier 把 candidate 实际写出来的内容和它自己脑补出来的内容显式分开评估,避免它"代笔"把不完整的 candidate 判成完美。这是整个框架最容易被忽视、但实际收益最大的设计点。
Mutation 要兼顾 exploit 与 explore。单一 mutation 算子容易陷入局部最优——只做 PATCH 模式的 refine 会无限优化一个方向错误的解,只做 REWRITE 又会把已经接近正确的解改坏。Dual refine(PATCH + REWRITE 并行)相当于一个粗粒度的 multi-objective mutation,让每一代都同时存在 conservative 和 aggressive 两种 offspring。
Selection 在 fitness 趋同时需要二阶信号。当群体里多个 individual fitness 都很接近时,单纯按 fitness 排序选不出最好的——这时候需要 pairwise comparison 提供二阶信号。Ranker tournament 就是这个角色:在 fitness 区分能力失效的区域,用直接的对比代替绝对打分。
Termination 不能只看 single-individual signal。早停规则必须依赖 population-level 的信号,因为 single individual 即便 fitness 满分也可能是 fitness function 的假阳性。要求 ≥2 个 individual 同时达到 fitness 上限再停,相当于用 population redundancy 来对冲 fitness function 自身的 noise。
M3 + MaxProof搜索过程
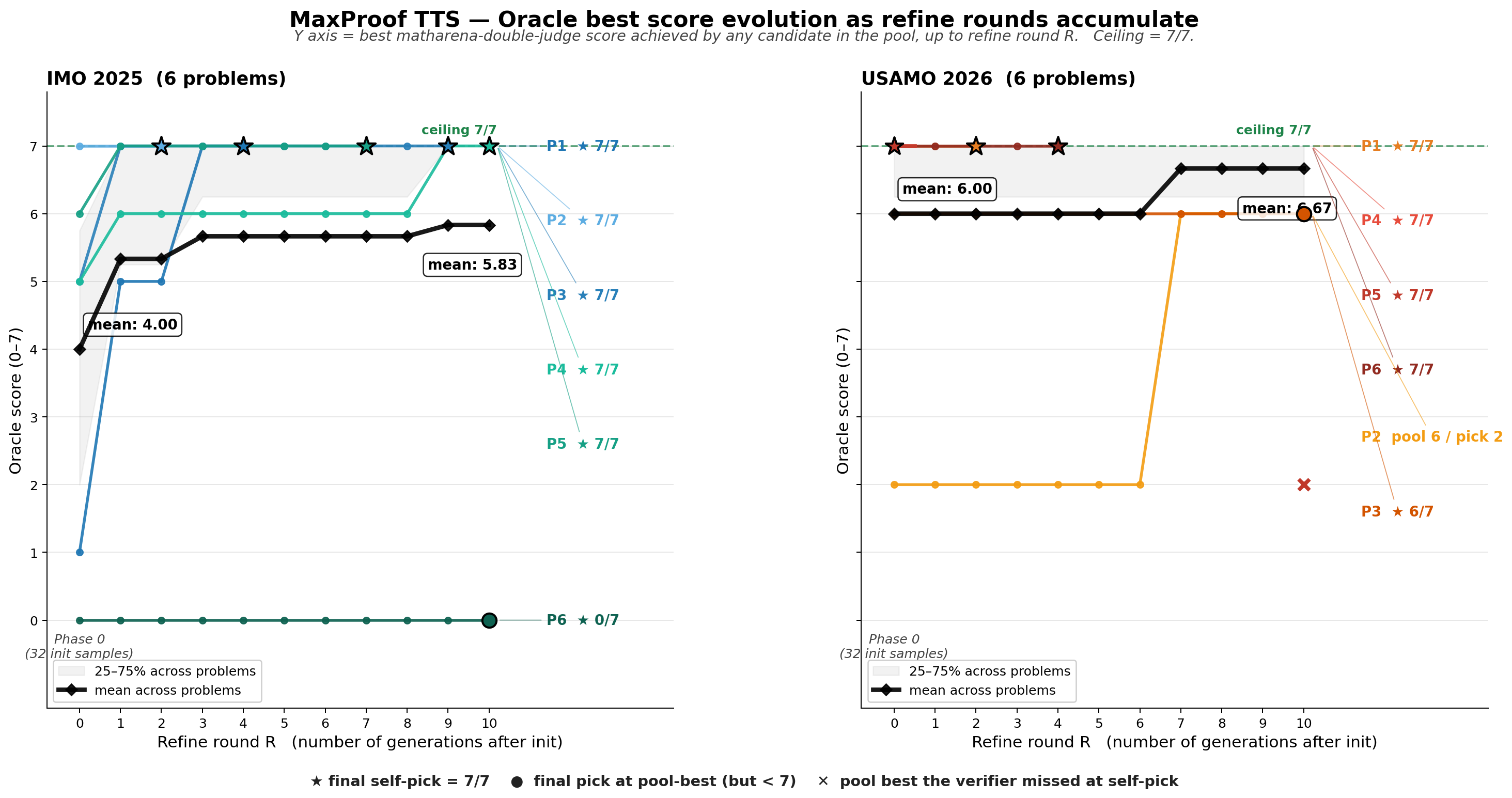
MaxProof 搜索过程中的 oracle best score evolution:横轴是 refine round,R=0 表示初始化采样阶段;纵轴是截至当前轮次,候选池中任一 candidate 达到的最好分数,满分为 7/7。黑线表示 6 道题的平均 oracle best score,星号表示最终 self-pick 结果,圆点表示 final pick 落在 pool-best 但仍未满分的位置,叉号表示候选池中存在更好解但 self-pick 未选中。
从搜索曲线看,MaxProof 的收益主要来自两个阶段。第一阶段是 population initialization:仅靠初始 32 个候选,部分题目已经能在 pool 中出现高分甚至满分解,这说明 M3 合板模型本身已经具备一定 best@K 能力。第二阶段是 iterative refinement:随着 PATCH / REWRITE 轮次累积,候选池中的 oracle best score 会继续抬升,尤其是在初始候选没有直接命中的题目上,refine 能够把已有候选的局部思路继续推进,或通过 rewrite 跳出原有错误方向。
总结与未来展望
在困难数学能力推进上,我们跟开闭源社区的顶尖水平依然有可见的差距。本文介绍的 Proof RL、Verifier Alignment 与 Refinement Augmentation 分别对应了三个核心能力。Proof RL 提升了模型从零生成证明的上限;Verifier Alignment 让模型具备更可问责的错误发现能力;Refinement Augmentation 则把 Proof RL 过程中自然产生的大量失败样本转化为修复能力训练数据。最终,MaxProof 把这些能力组织成一个 population-level 的进化搜索框架,把 best@K 能力转化为更稳定的最终输出。
数学证明是检验模型可靠推理能力的高压场景。它要求模型不仅能给出看似合理的答案,还要在长链条、强约束、低容错的环境中持续保持正确。其中 generative verifier 的核心实践经验尤其明确:用于 RL reward 的 verifier,首要目标不是在静态 benchmark 上获得最高平均准确率,而是构建一个低 false positive、可持续监控、难以被 policy 利用的可信奖励系统,这些都是让 generative verifier 真正可用的必要工程约束。MaxProof 是我们在这个方向上的一次阶段性尝试。