MiniMax M3
前沿 Coding & Agentic 能力· 百万上下文 · 原生多模态
首个三项能力兼备的国产旗舰,第一个把完整前沿能力带进开放世界的模型
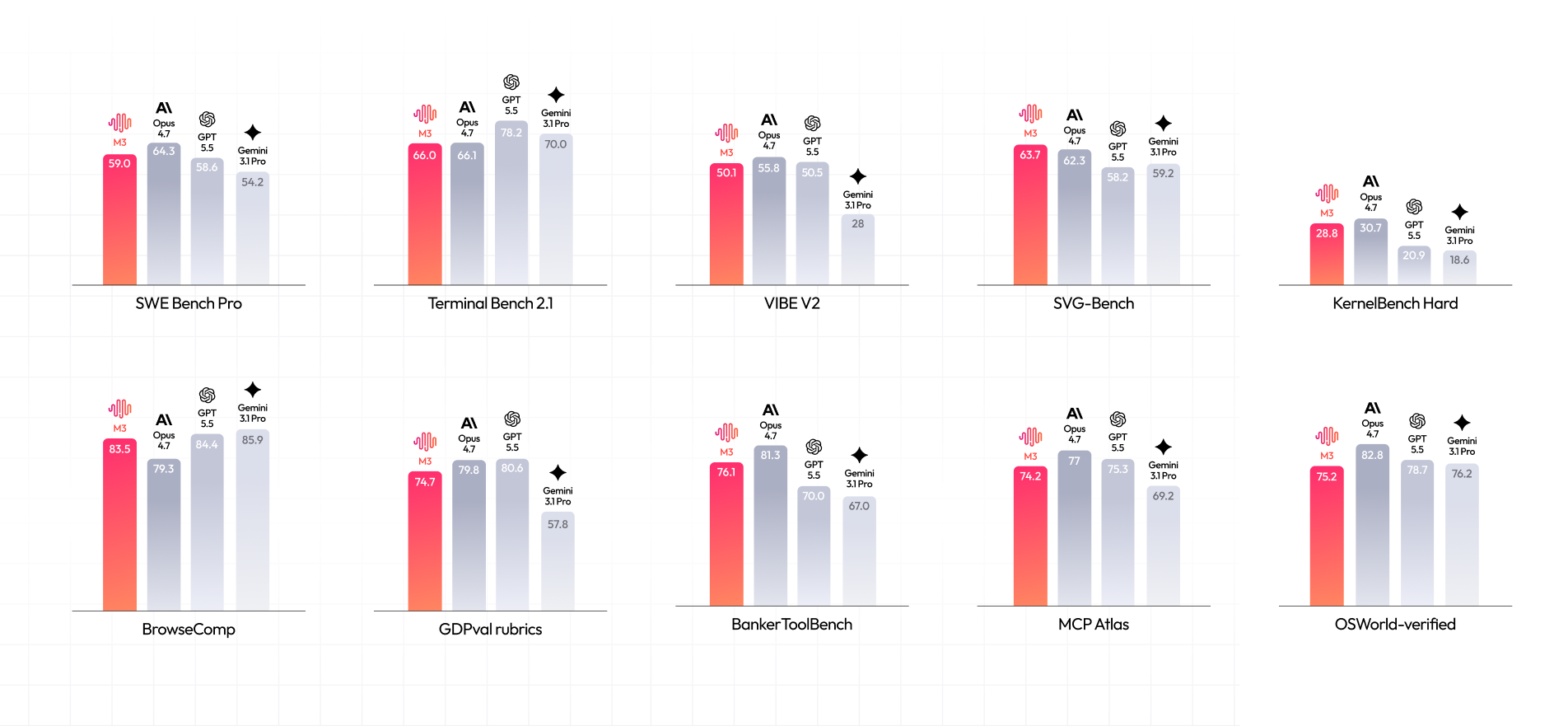
性能基准测试
M3 在编码与智能体评测中达到行业顶尖水平,具备自主任务拆解、工具调用与多步推理能力,写出的代码目标是直接可交付,而不是「能跑但需要人改」。
基于自研 MiniMax Sparse Attention(MSA)架构,API 最高支持 1M tokens 上下文窗口,保障至少 512K tokens 可用。1M 上下文是长程 Agent、长程 Coding、长视频理解的基础设施。
M3 是原生多模态模型,从第零步开始多模态训练,使文本和视觉语义空间高度对齐。多模态是刻在模型骨子里的原生能力,而非后期贴上去的浅表图层。
在 BrowseComp 智能体评测中,M3 以 83.5 分超越 Opus 4.7(79.3),展现出强大的自主浏览与信息检索能力。
能同时跑通编码能力前沿、百万上下文和原生多模态的此前只有极少数闭源模型,M3 是第一个把完整 frontier 能力带进开放世界的模型。
基准测试
Coding 与 Agent 能力是 M3 重点提升之处,在涵盖软件工程、终端执行等多个维度的国际权威评测中,M3 均达到国际领先水平。
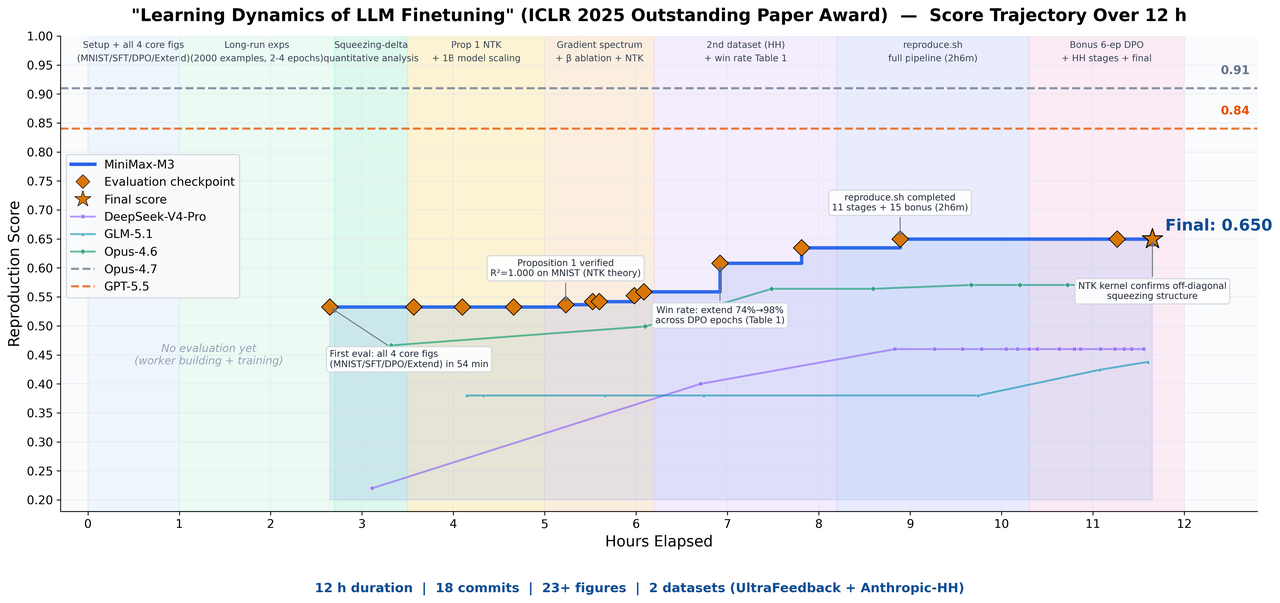
论文复现:12 小时自主完成 ICLR 杰出论文
我们丢给 M3 一篇 ICLR 2025 杰出论文 — Learning Dynamics of LLM Finetuning,让它独立复现。M3 连续运行近 12 小时,全程自主产出 18 次 commit 与 23 张实验图表,成功跑通核心实验。多模态看懂论文里的图表公式,长上下文保证论文 + 代码 + 实验日志一次性进窗口,编程 + Agent 能力驱动长线程执行。
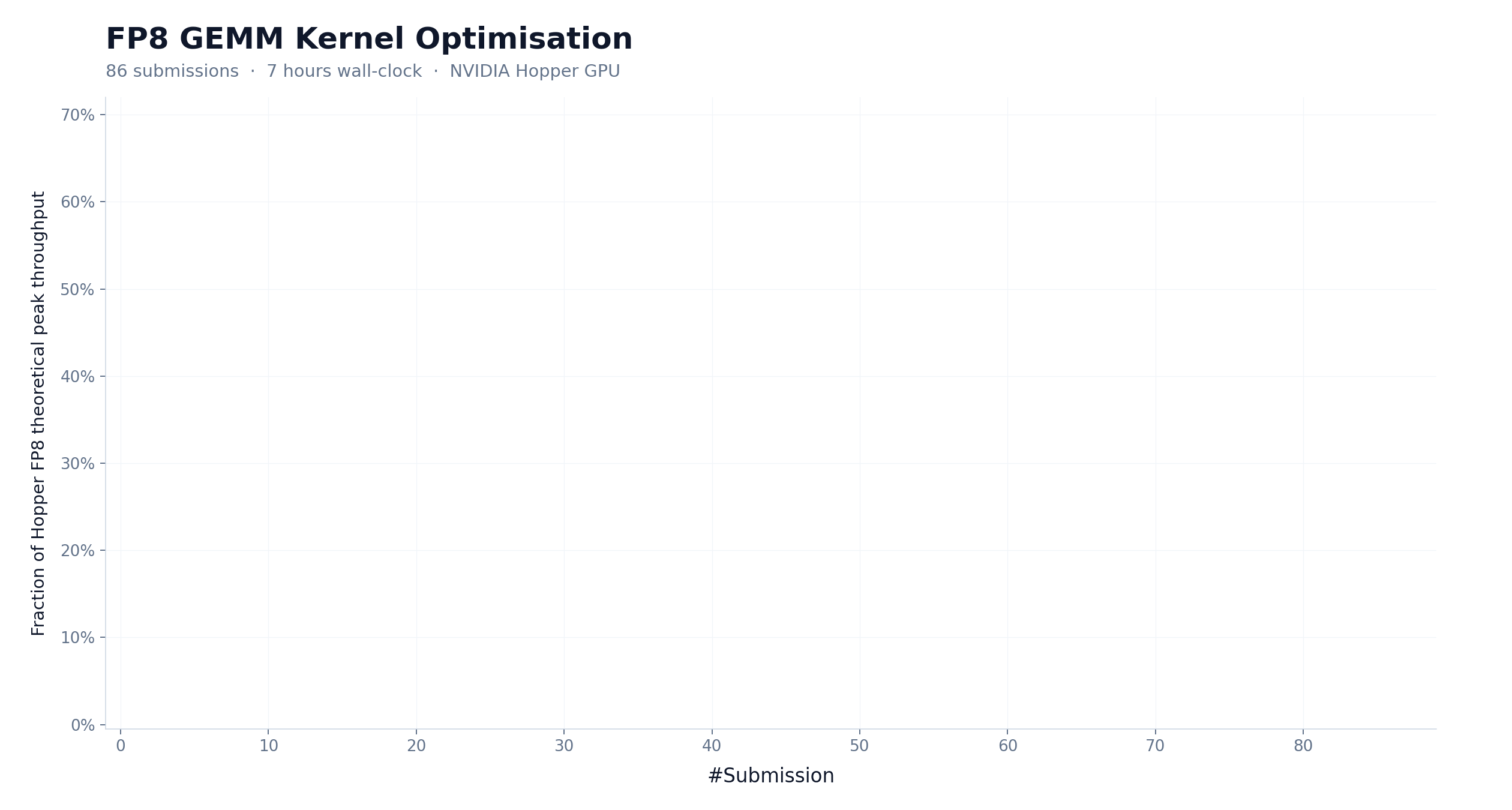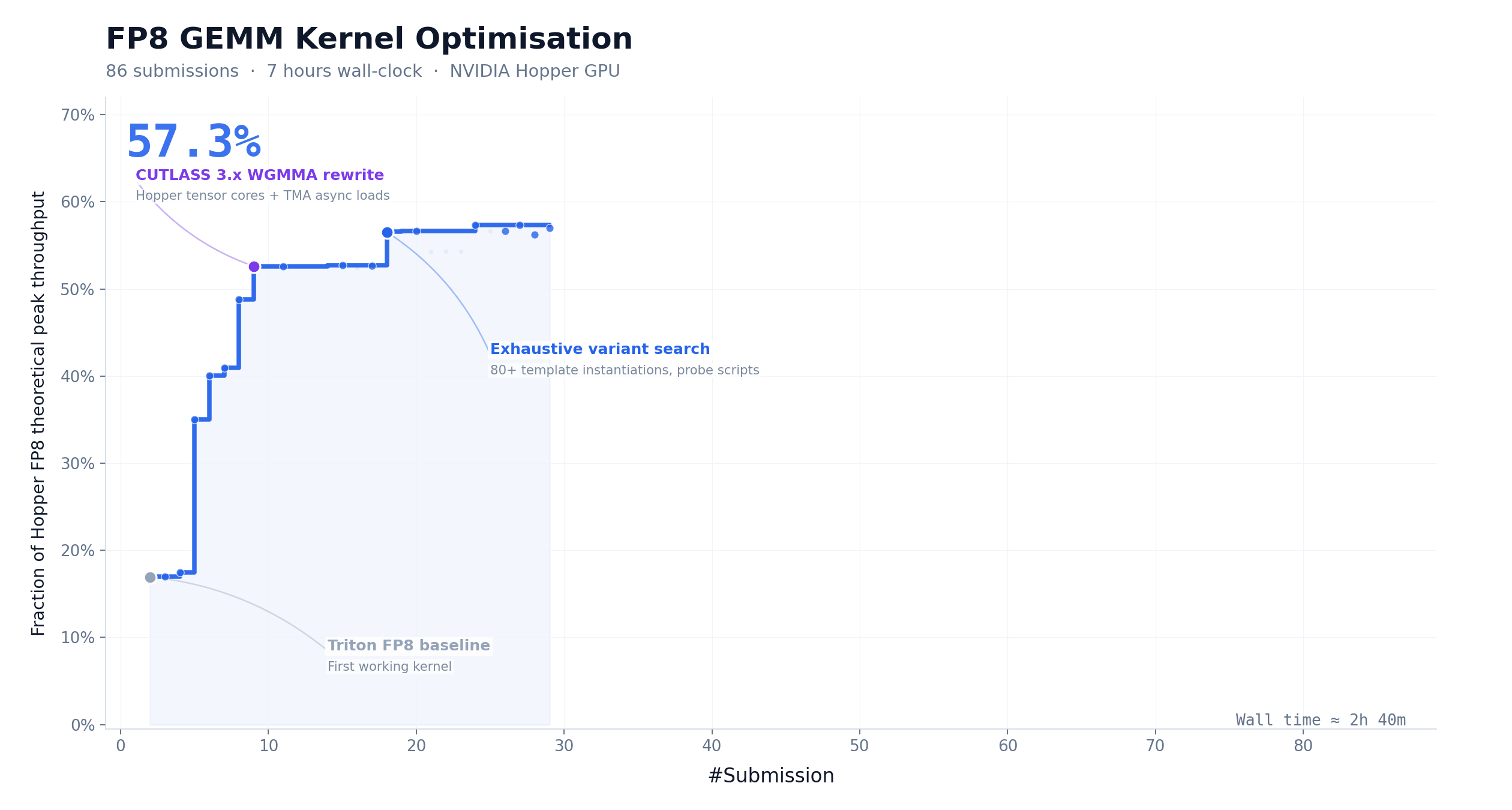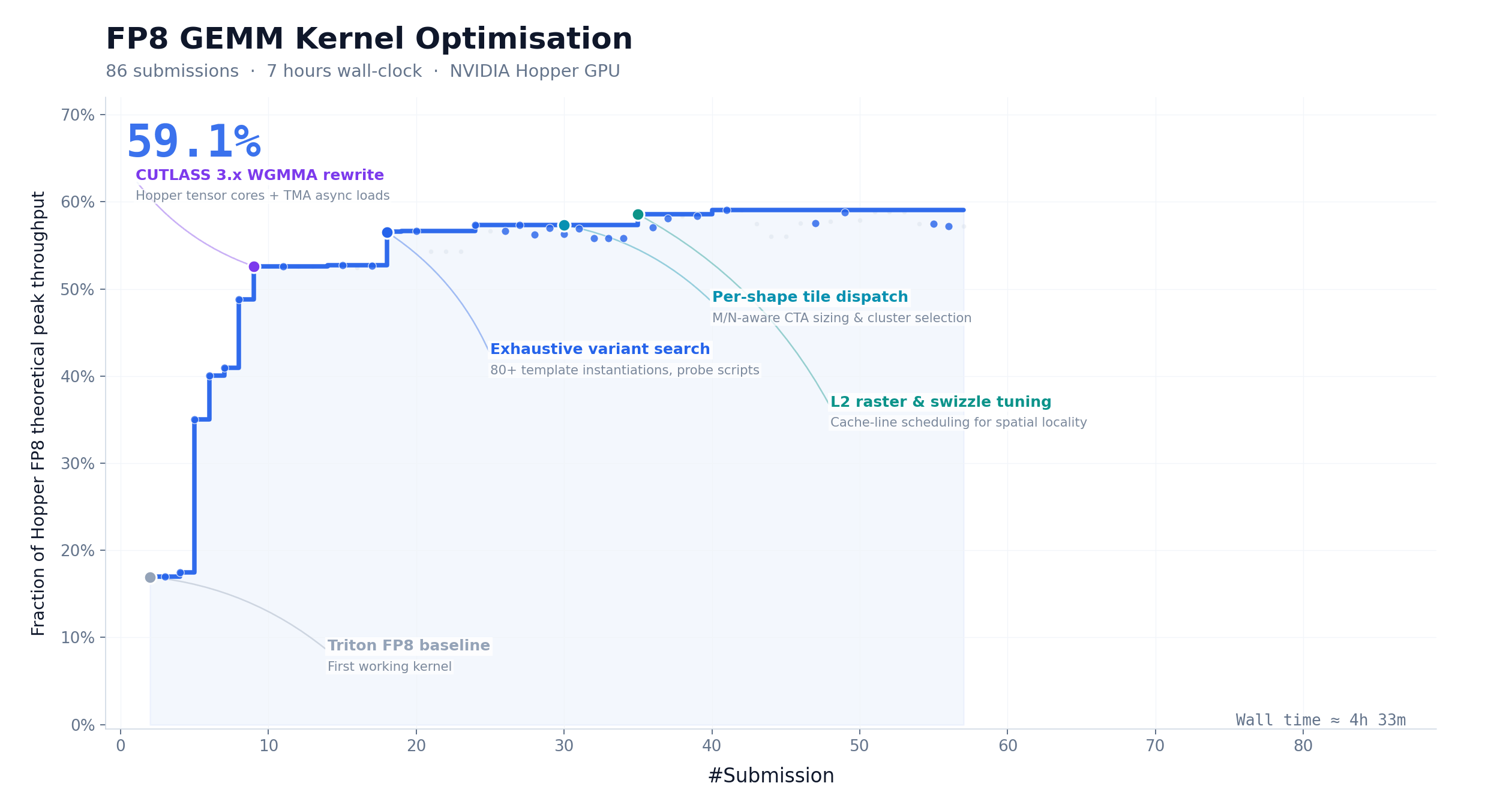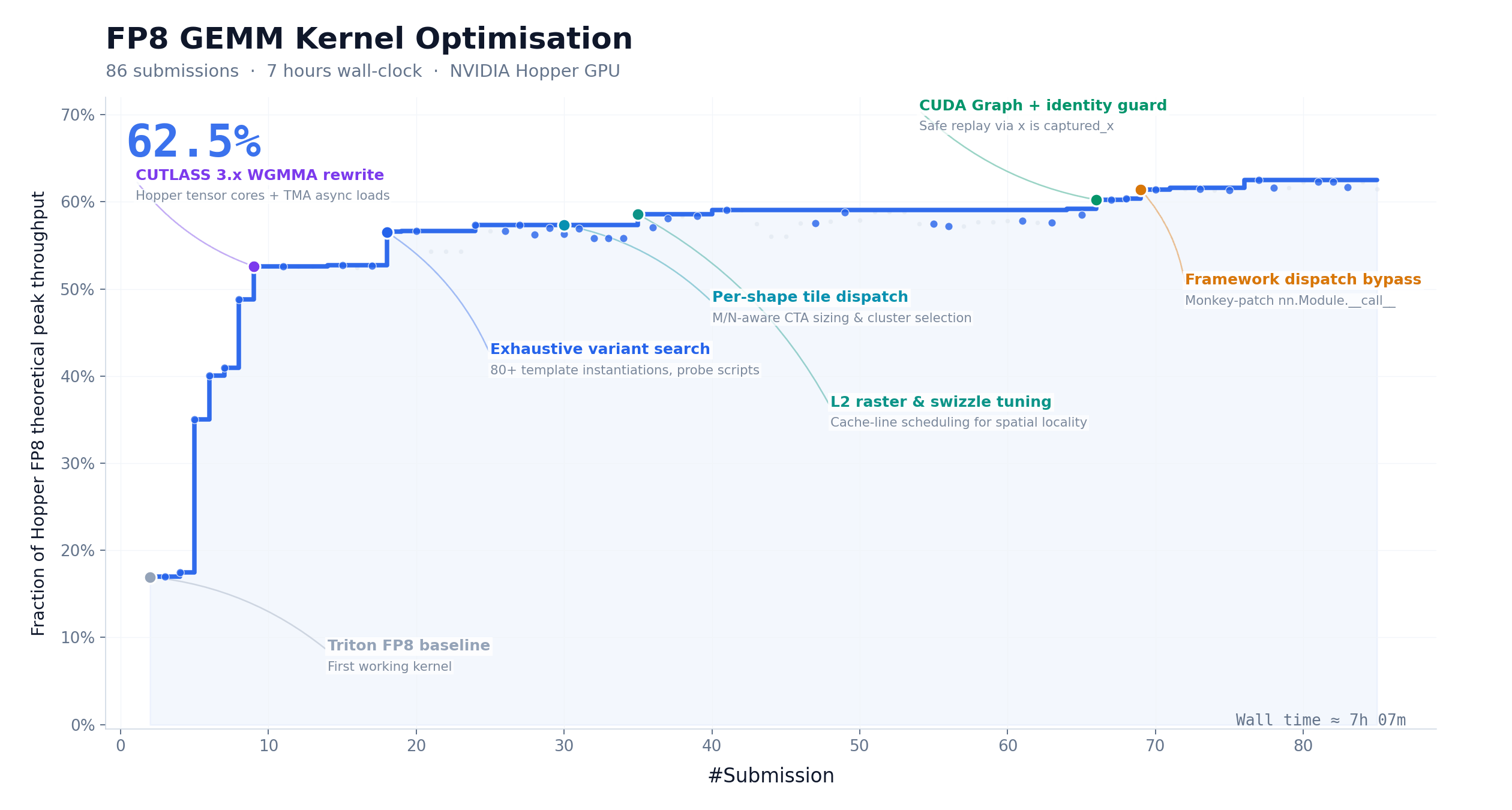
CUDA 算子优化:147 次迭代,9.4× 加速
FP8 矩阵乘是大模型推理计算量最集中的环节之一。我们让 M3 在 NVIDIA Hopper 架构上优化该 kernel,起点仅有任务描述和一个无法运行的 Triton 骨架。M3 在约 24 小时内完成 147 次 benchmark 提交、1959 次工具调用,将硬件峰值利用率从 7.6% 推进至 71.3%,实现 9.4× 加速——全程零人工介入。
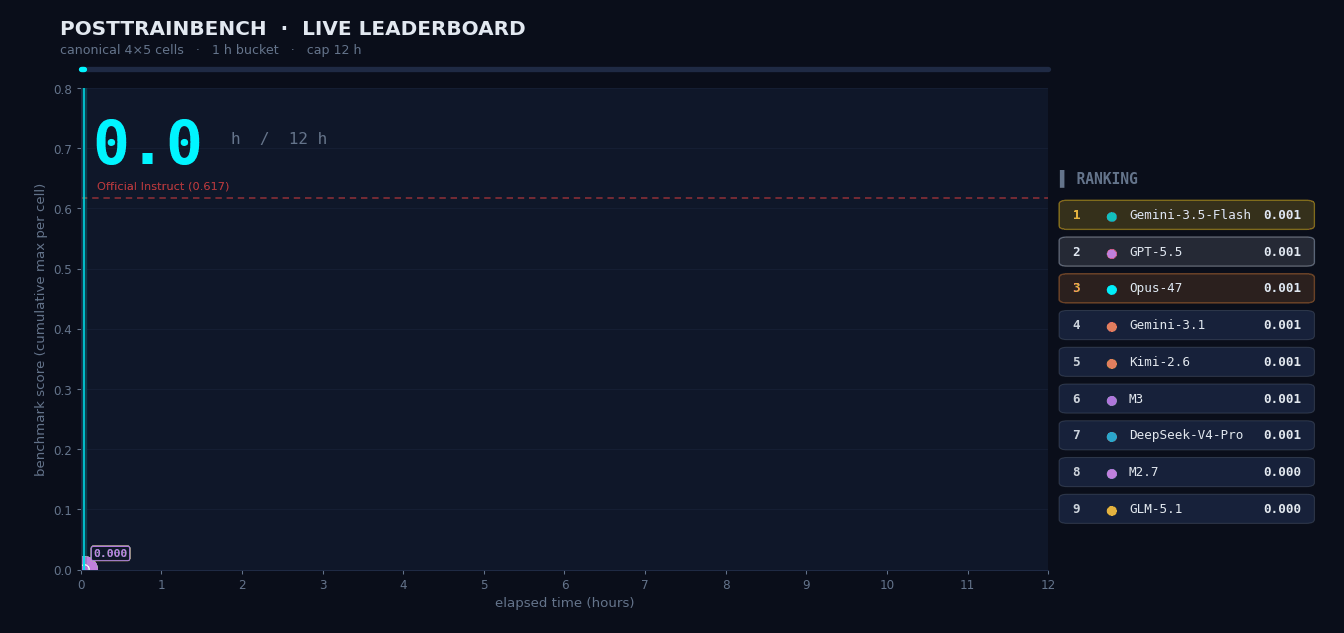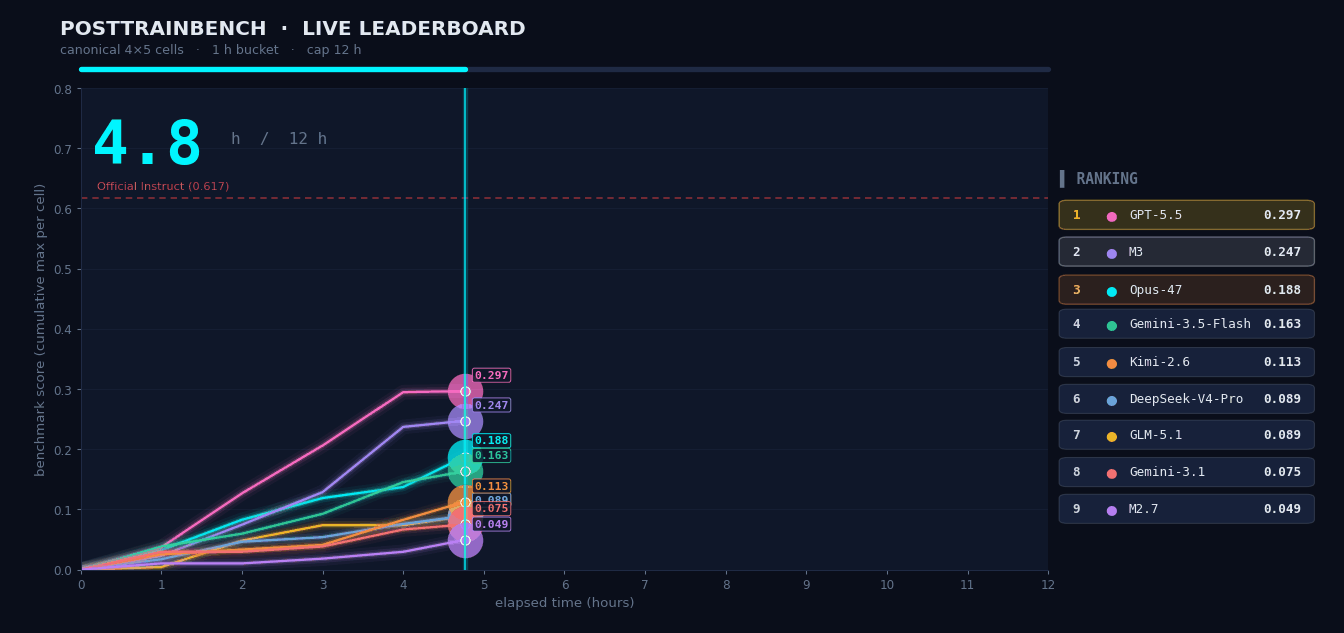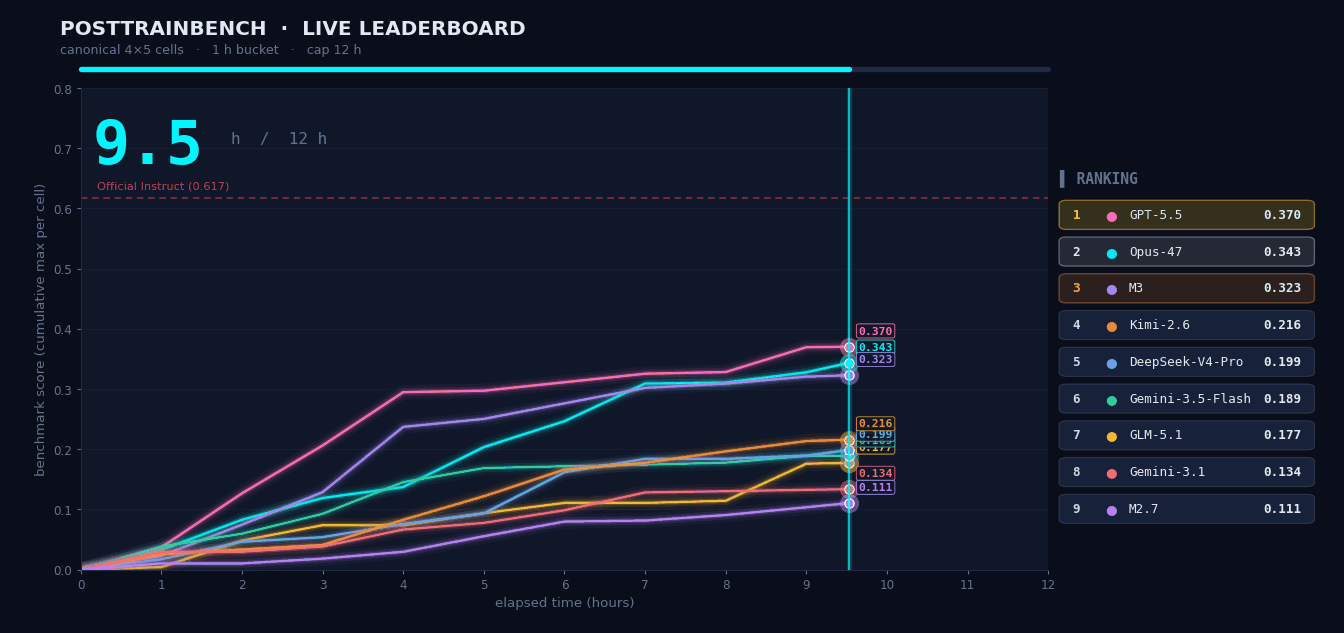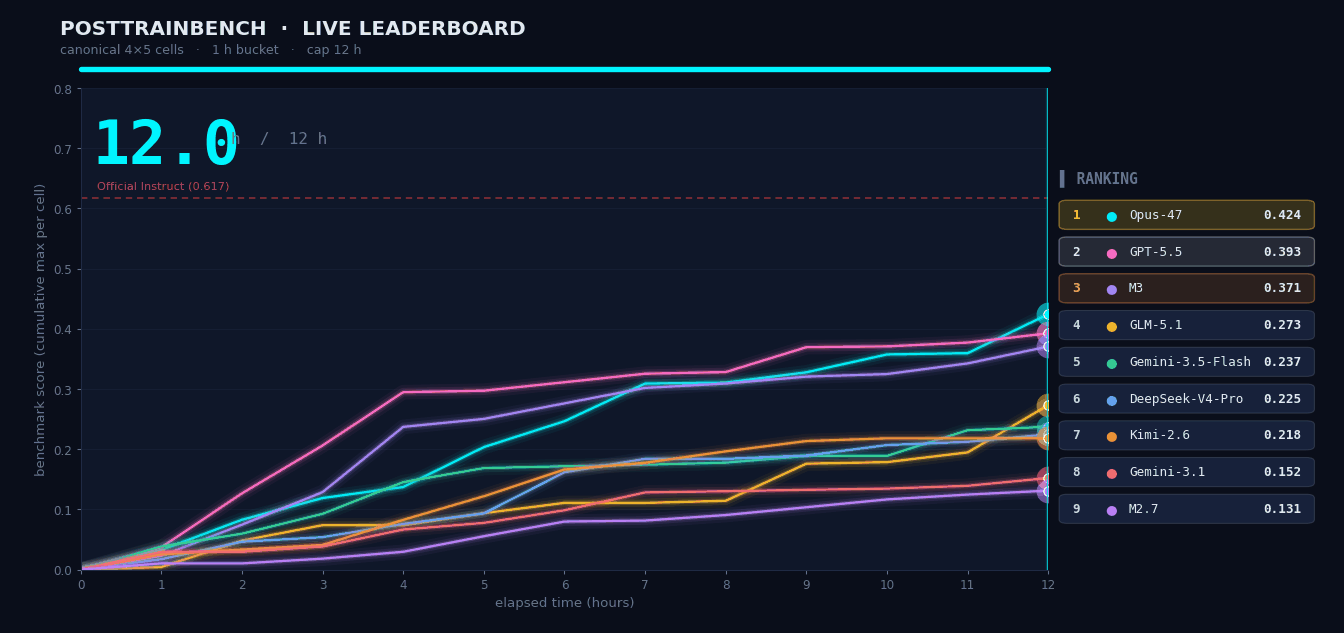
PostTrainBench:让 M3 自己「训」模型
给 M3 四个只完成预训练的 Base 模型,要求在 12 小时内自主完成数据合成、训练、评测、迭代全流程,让它们在数学推理、代码生成、知识问答等任务上具备能力。整个流程全程无人干预,M3 最终得分 37.1,位列第三,仅次于 Opus 4.7(42.4)和 GPT-5.5(39.3),明显领先其余模型。
生成专属邀请码
邀请好友, 福利加倍
好友完成Token Plan订阅可享9折优惠,邀请者获10%代金券返利!
生成专属邀请码邀请好友, 福利加倍
好友完成Token Plan订阅可享9折优惠,邀请者获10%代金券返利!
DEVELOPER TOOLS
赋予开发者选择权
卓越的工具脚手架泛化能力










01 / 接入方式
API 快速接入
全面支持自动 Cache,无需设置,自动生效。